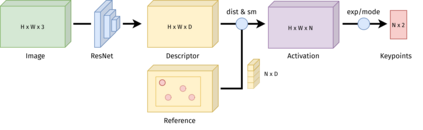
In recent years, policy learning methods using either reinforcement or imitation have made significant progress. However, both techniques still suffer from being computationally expensive and requiring large amounts of training data. This problem is especially prevalent in real-world robotic manipulation tasks, where access to ground truth scene features is not available and policies are instead learned from raw camera observations. In this paper, we demonstrate the efficacy of learning image keypoints via the Dense Correspondence pretext task for downstream policy learning. Extending prior work to challenging multi-object scenes, we show that our model can be trained to deal with important problems in representation learning, primarily scale-invariance and occlusion. We evaluate our approach on diverse robot manipulation tasks, compare it to other visual representation learning approaches, and demonstrate its flexibility and effectiveness for sample-efficient policy learning.
翻译:近年来,利用强化或仿照的政策学习方法取得了显著进展,然而,这两种技术仍然在计算费用昂贵,需要大量培训数据,这个问题在现实世界的机器人操纵任务中特别普遍,在实际操作任务中,无法接触地面真相现场特征,而是从原始相机观测中学习政策。在本文中,我们通过Dense Correpositence 借口任务,展示了学习图像关键点对下游政策学习的功效。我们把先前的工作扩大到挑战性多对象场景,我们表明我们的模型可以接受培训,处理代表性学习方面的重要问题,主要是规模差异和隔离。我们评估了我们关于各种机器人操作任务的方法,将其与其他视觉演示学习方法进行比较,并展示其灵活性和有效性,以便进行抽样有效的政策学习。