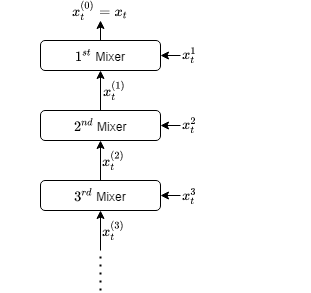
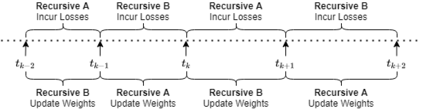
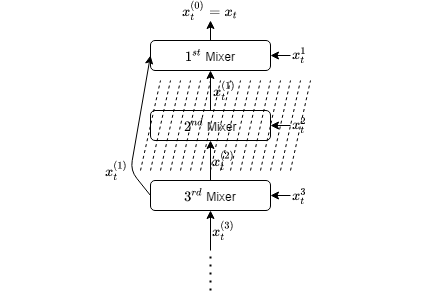
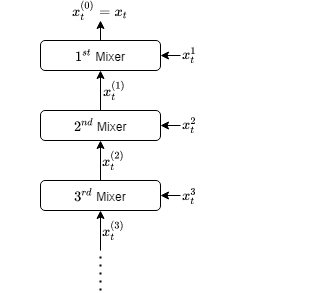
We introduce an online convex optimization algorithm using projected subgradient descent with optimal adaptive learning rates, with sequential and efficient first-order updates. Our method provides a subgradient adaptive minimax optimal dynamic regret guarantee for a sequence of general convex functions with no known additional properties such as strong-convexity, smoothness, exp-concavity or even Lipschitz-continuity. The guarantee is against any comparator decision sequence with bounded "complexity", defined by the cumulative distance traveled via changes between successive decisions. We show optimality by generating a lower bound of the worst-case second-order dynamic regret, which incorporates actual subgradient norms and matches with our guarantees within a constant factor. We also derive the extension for independent learning in each decision coordinate separately. Additionally, we demonstrate how to best preserve our guarantees when the bound on total successive changes in the dynamic comparator sequence grows in time or the feedback regarding such bound arrives partially with time, both in a truly online manner. Then, as a major contribution, we examine the scenario when we receive no information regarding the successive changes, but instead, by a unique re-purposing of the expert mixture framework with novel additions, we eliminate the need of such information in, again, a truly online manner. Moreover, we show the ability to compete against all dynamic comparator sequences simultaneously (universally) with minimax optimality, where the guarantees depend on the "complexity" of each comparator separately. We also discuss potential modifications to our approach which addresses further complexity reductions for time, computation, memory, and we also further the universal competitiveness via guarantees taking into account concentrations of a comparator sequence in the decision set.
翻译:我们使用预测的亚梯度下降和最佳适应性学习率进行在线 convex优化算法,使用预测的亚梯度下降和最佳适应性学习率,并按顺序和高效的一级更新。我们的方法提供了一种亚梯度适应性适应性小型小型最优化动态遗憾保证,用于一系列一般 convex功能,没有已知的其他特性,如强调、光滑、变速、变速、甚至利普西茨-连续性。保证是对任何参照者决定序列的“复杂性”进行在线约束的。然后,作为主要贡献,我们通过生成最坏的第二级动态遗憾,降低范围较低,纳入实际的次级规范,与我们的保证相匹配。我们还为每项决定的独立学习提供扩展,同时进行单独的协调。此外,我们证明当动态参照者序列的全局性变化在时间里拉长,或者关于这种联系的反馈部分随着时间(通过在线方式)的累积而出现。然后,当我们没有收到关于连续变化的信息时,我们就会看到最优化的情景,我们又会看到最佳的情景,相反,我们通过一种独特的回溯的回溯的回调, 通过一种特殊的回溯的比较性的方法, 通过一种特殊的回溯的回溯的方法,我们是如何去一个特殊的回溯的回溯的回溯到一个动态的回溯的回溯的回溯的回溯的回溯的回溯的回溯的回溯的回溯的回溯的回的回溯的回溯的回溯的回的回的回的递率,我们, 一种推的递率, 一种推的回的回的回的回的推论,也就是我们是如何的回的回的回的回的回的递式的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的回的