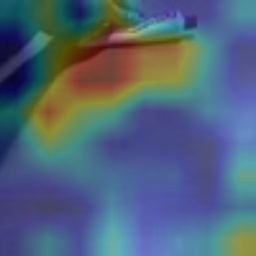
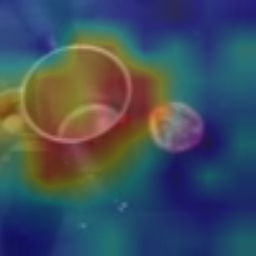
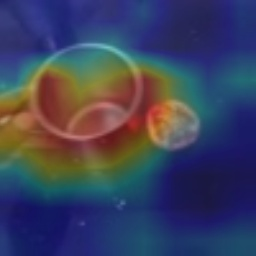
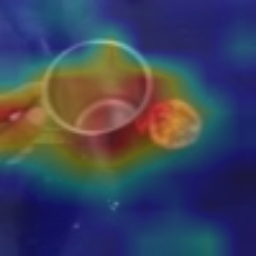
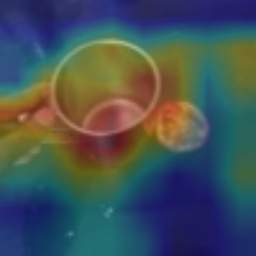
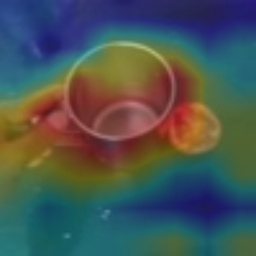
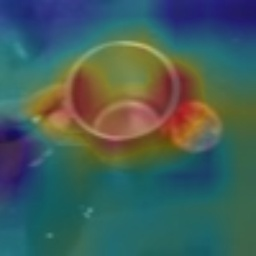
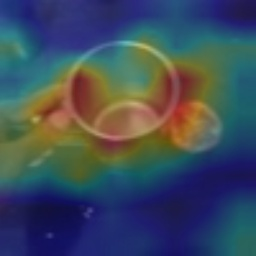
Visual tempo, which describes how fast an action goes, has shown its potential in supervised action recognition. In this work, we demonstrate that visual tempo can also serve as a self-supervision signal for video representation learning. We propose to maximize the mutual information between representations of slow and fast videos via hierarchical contrastive learning (VTHCL). Specifically, by sampling the same instance at slow and fast frame rates respectively, we can obtain slow and fast video frames which share the same semantics but contain different visual tempos. Video representations learned from VTHCL achieve the competitive performances under the self-supervision evaluation protocol for action recognition on UCF-101 (82.1\%) and HMDB-51 (49.2\%). Moreover, comprehensive experiments suggest that the learned representations are generalized well to other downstream tasks including action detection on AVA and action anticipation on Epic-Kitchen. Finally, we propose Instance Correspondence Map (ICM) to visualize the shared semantics captured by contrastive learning.
翻译:在这项工作中,我们证明视觉节奏也可以作为视频演示学习的自我监督信号。我们提议通过分级对比学习(VTHCL)最大限度地扩大慢速视频和快速视频展示之间的相互信息。具体地说,通过分别以慢速和快速框架速对相同实例进行抽样抽样,我们可以得到共享语义但包含不同视觉节奏的慢速视频框架。从VTHCL学到的视频演示能够根据自我监督评估协议实现识别UCF-101(821. ⁇ )和HMDB-51(49.2 ⁇ )的行动评估协议的竞争性表演。此外,全面实验表明,所学到的演示非常广泛,与其他下游任务相近,包括AVA的行动探测和Epic-Kitchen的行动预期。最后,我们建议试样Correspondenence 地图(ICM)将对比性学习所捕捉到的共同语义进行直观化。