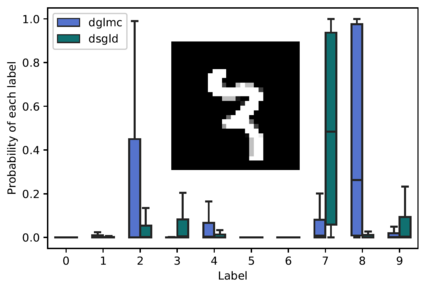
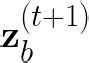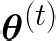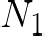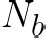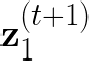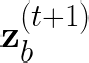Performing reliable Bayesian inference on a big data scale is becoming a keystone in the modern era of machine learning. A workhorse class of methods to achieve this task are Markov chain Monte Carlo (MCMC) algorithms and their design to handle distributed datasets has been the subject of many works. However, existing methods are not completely either reliable or computationally efficient. In this paper, we propose to fill this gap in the case where the dataset is partitioned and stored on computing nodes within a cluster under a master/slaves architecture. We derive a user-friendly centralised distributed MCMC algorithm with provable scaling in high-dimensional settings. We illustrate the relevance of the proposed methodology on both synthetic and real data experiments.
翻译:在大数据尺度上进行可靠的贝叶斯推论正在成为现代机器学习时代的基石。 完成这项任务的一组方法是Markov连锁Monte Carlo(MCMC)算法,其处理分布式数据集的设计是许多工作的主题。 但是,现有方法既不完全可靠,也不完全可靠,也不具有计算效率。 在本文中,我们提议填补这一空白,即数据集在主控/奴隶结构下的一个集群内进行分割并存储在计算节点时。我们得出了一个方便用户的中央集成式MCMC算法,在高维环境中可以进行可辨称的缩放。我们举例说明了拟议方法对于合成和真实数据实验的相关性。