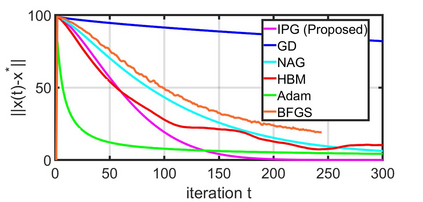
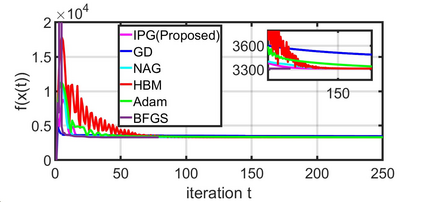
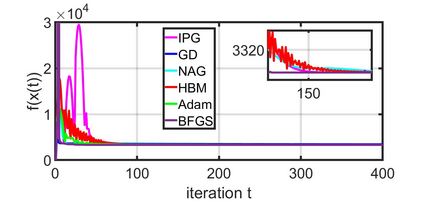
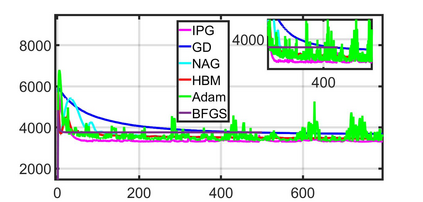
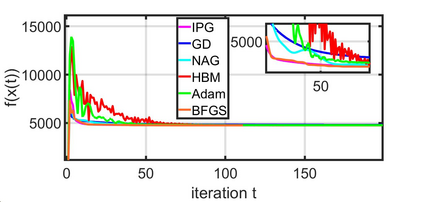
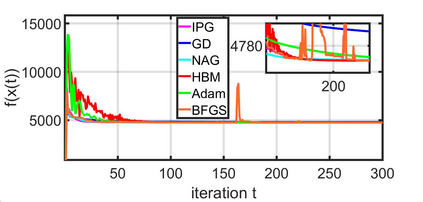
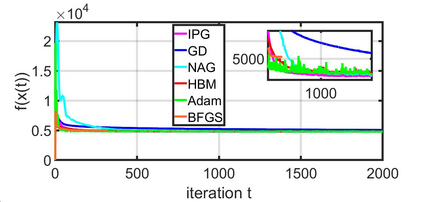
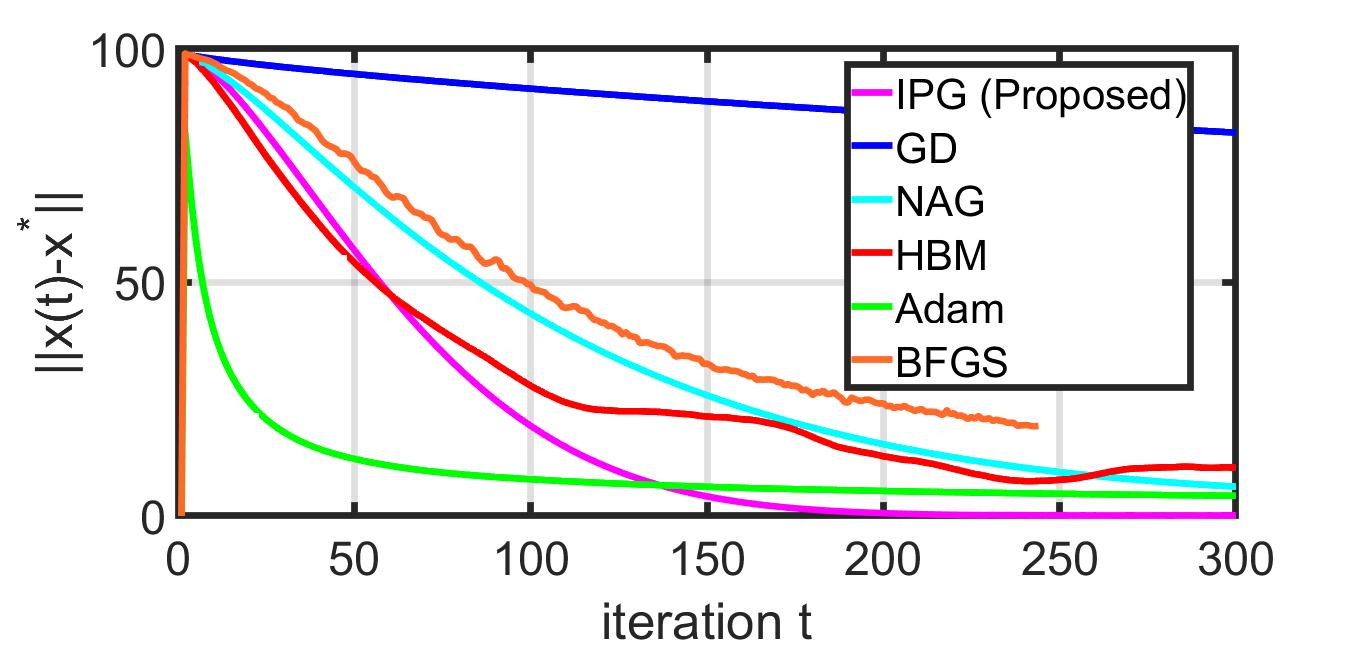
This paper studies a distributed multi-agent convex optimization problem. The system comprises multiple agents in this problem, each with a set of local data points and an associated local cost function. The agents are connected to a server, and there is no inter-agent communication. The agents' goal is to learn a parameter vector that optimizes the aggregate of their local costs without revealing their local data points. In principle, the agents can solve this problem by collaborating with the server using the traditional distributed gradient-descent method. However, when the aggregate cost is ill-conditioned, the gradient-descent method (i) requires a large number of iterations to converge, and (ii) is highly unstable against process noise. We propose an iterative pre-conditioning technique to mitigate the deleterious effects of the cost function's conditioning on the convergence rate of distributed gradient-descent. Unlike the conventional pre-conditioning techniques, the pre-conditioner matrix in our proposed technique updates iteratively to facilitate implementation on the distributed network. In the distributed setting, we provably show that the proposed algorithm converges linearly with an improved rate of convergence than the traditional and adaptive gradient-descent methods. Additionally, for the special case when the minimizer of the aggregate cost is unique, our algorithm converges superlinearly. We demonstrate our algorithm's superior performance compared to prominent distributed algorithms for solving real logistic regression problems and emulating neural network training via a noisy quadratic model, thereby signifying the proposed algorithm's efficiency for distributively solving non-convex optimization. Moreover, we empirically show that the proposed algorithm results in faster training without compromising the generalization performance.
翻译:本文研究一个分布式多试剂粉色优化问题。 系统由这一问题的多个代理商组成, 每个都有一套本地数据点和相关的本地成本功能。 代理商连接到服务器, 没有代理商之间的通信。 代理商的目标是学习一个参数矢量, 该参数矢量优化当地成本的总和, 而不披露其本地数据点 。 原则上, 代理商可以通过使用传统的分布式梯度- 荧光方法与服务器合作解决这个问题 。 但是, 当总成本条件欠佳时, 梯度- 白程方法 (一) 需要大量迭代, 并且(二) 与进程噪音高度不稳定 。 我们提议一个迭代前调节技术来减轻成本函数对分布式梯度- 亮度的趋同率的有害影响 。 与常规的预设条件矩阵是反复更新, 以便利分布式网络的实施。 在分布式网络中, 我们提议的递增率- 递增法将我们的拟议递增性递增率比常规和调性精度的精度递增率递增率递增率率, 我们提出的递增性总级- 的递增性递增性递校程的递增性递增性计算表现显示我们的特殊例中, 。