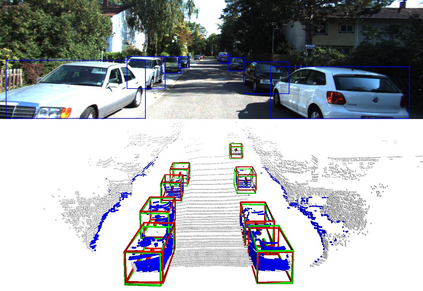
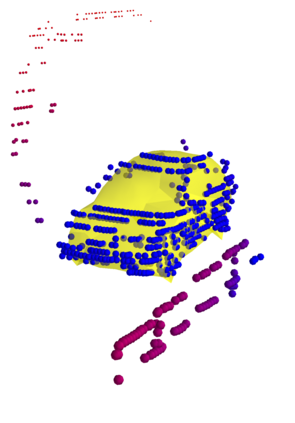
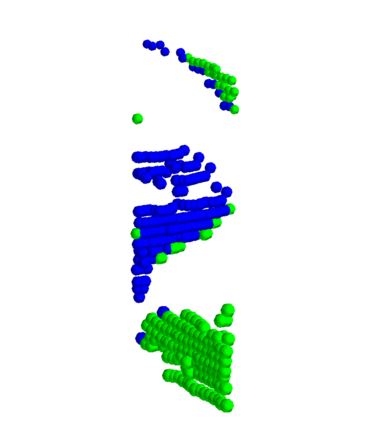
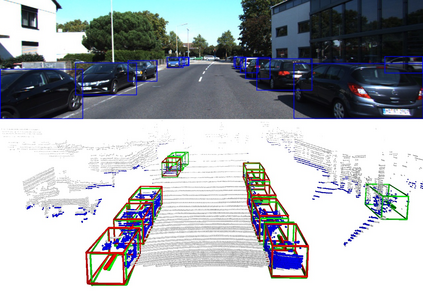
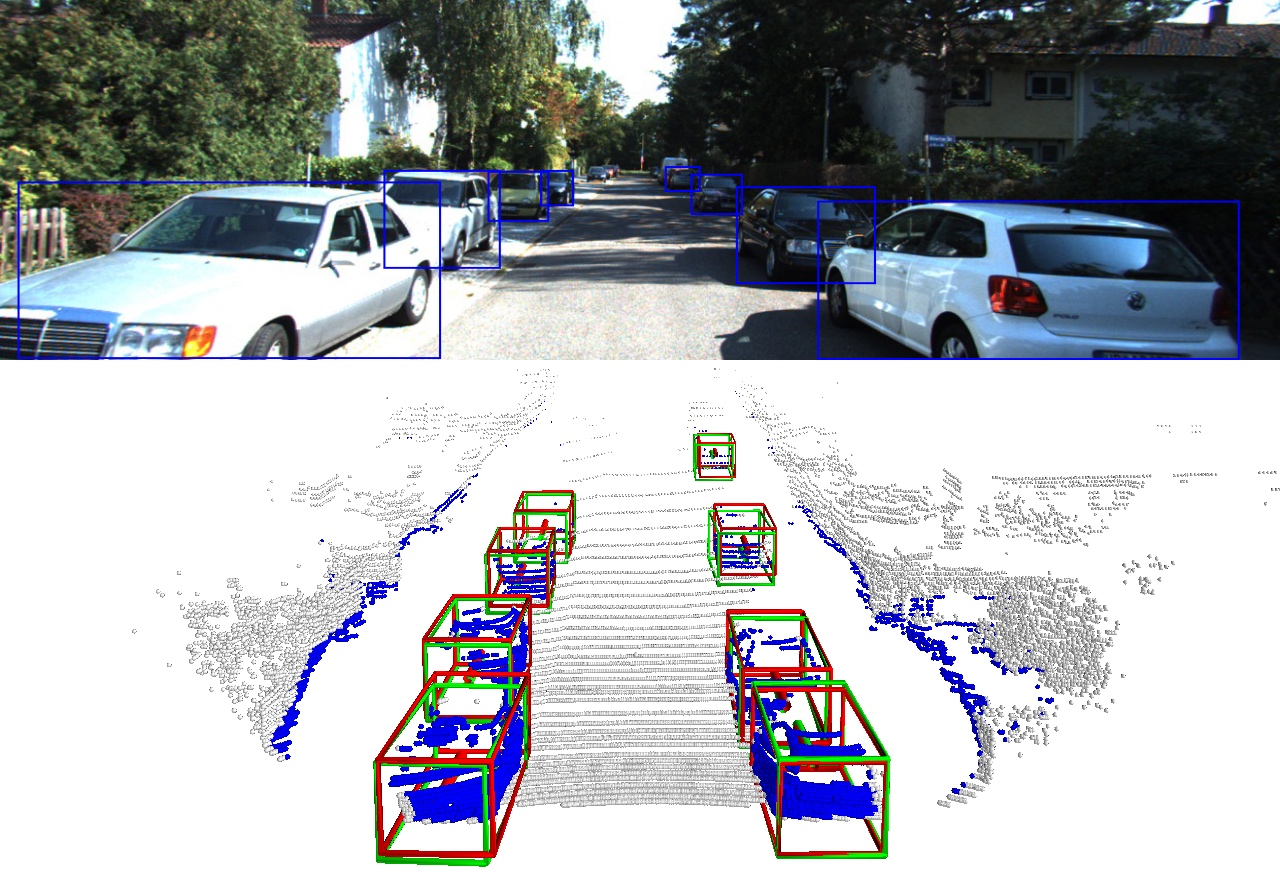
We present a system for automatic converting of 2D mask object predictions and raw LiDAR point clouds into full 3D bounding boxes of objects. Because the LiDAR point clouds are partial, directly fitting bounding boxes to the point clouds is meaningless. Instead, we suggest that obtaining good results requires sharing information between \emph{all} objects in the dataset jointly, over multiple frames. We then make three improvements to the baseline. First, we address ambiguities in predicting the object rotations via direct optimization in this space while still backpropagating rotation prediction through the model. Second, we explicitly model outliers and task the network with learning their typical patterns, thus better discounting them. Third, we enforce temporal consistency when video data is available. With these contributions, our method significantly outperforms previous work despite the fact that those methods use significantly more complex pipelines, 3D models and additional human-annotated external sources of prior information.
翻译:我们提出了一个将 2D 掩码对象预测和原始 LiDAR 点云自动转换成完整的 3D 边框对象的系统。 因为 LiDAR 点云是局部的, 直接将捆绑的框与点云连接起来是毫无意义的。 相反, 我们建议, 要取得良好的结果, 数据集中的 \ emph{all} 对象之间需要通过多个框架共享信息。 然后我们改进了三次基线。 首先, 我们解决了通过直接优化空间预测物体旋转的模糊性, 同时仍然通过模型回溯旋转的预测。 其次, 我们明确建模外端, 并责成网络学习其典型模式, 从而更好地打折扣 。 第三, 当有视频数据时, 我们强制时间的一致性。 有了这些贡献, 我们的方法大大超越了先前的工作, 尽管这些方法使用了更复杂的管道、 3D 模型 和 附加人文注释的外部信息源 。