
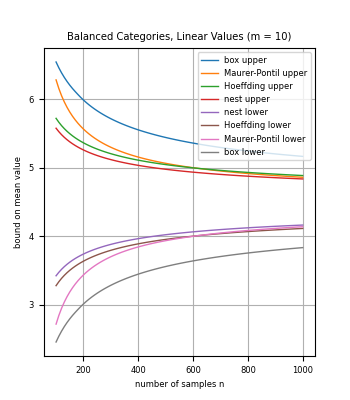
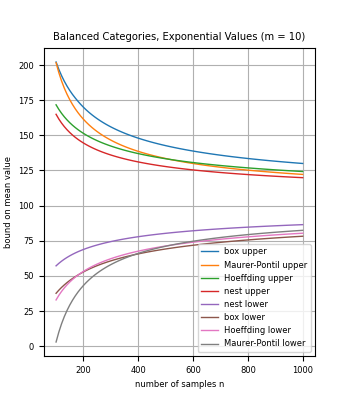
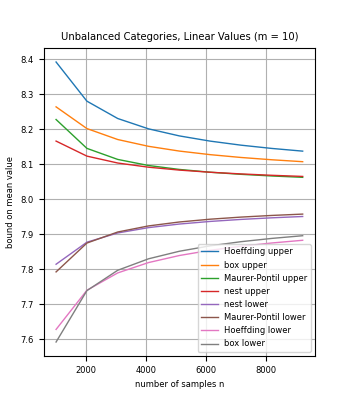
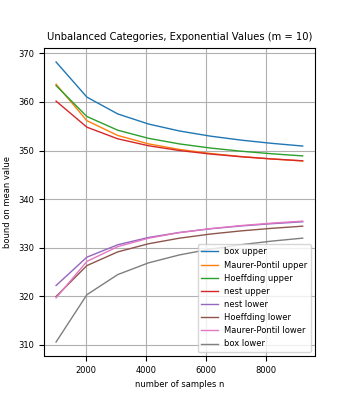
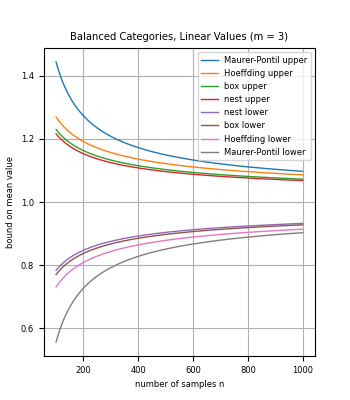
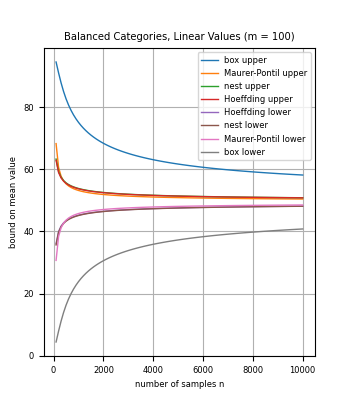
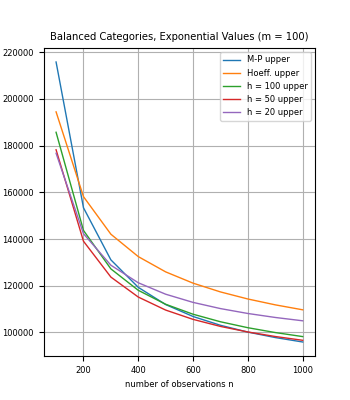
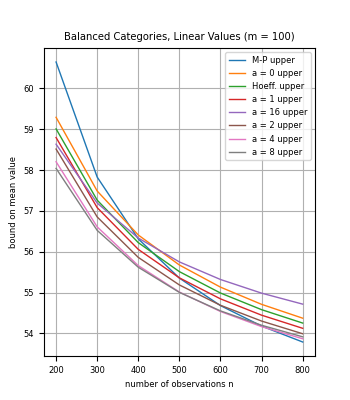
We introduce methods to bound the mean of a discrete distribution (or finite population) based on sample data, for random variables with a known set of possible values. In particular, the methods can be applied to categorical data with known category-based values. For small sample sizes, we show how to leverage knowledge of the set of possible values to compute bounds that are stronger than for general random variables such as standard concentration inequalities.
翻译:我们引入了基于抽样数据的离散分布(或有限人口)平均值约束方法,用于随机变量,并设定已知的一组可能的值。 特别是,这些方法可以适用于已知的类别值的绝对数据。 对于小样本大小,我们展示了如何利用对一组可能值的知识来计算比标准浓度不平等等一般随机变量更强的界限。
相关内容

Arxiv
0+阅读 · 2021年10月27日
Arxiv
0+阅读 · 2021年10月27日
Arxiv
0+阅读 · 2021年10月26日
Arxiv
11+阅读 · 2021年9月3日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年10月27日
Arxiv
0+阅读 · 2021年10月27日
Arxiv
0+阅读 · 2021年10月26日
Arxiv
11+阅读 · 2021年9月3日