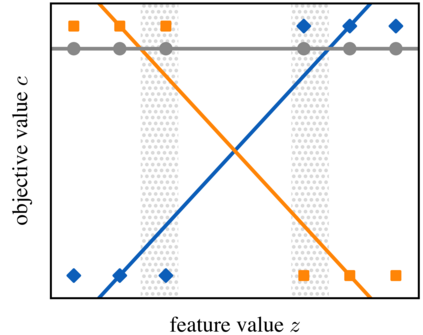
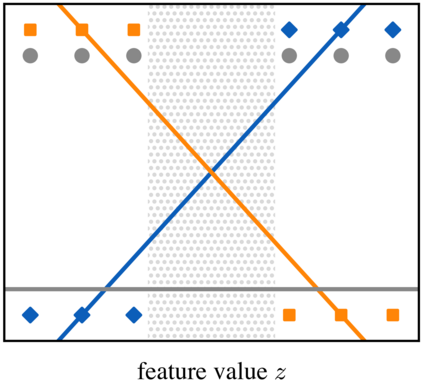
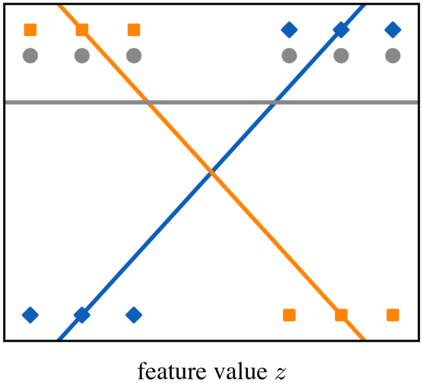
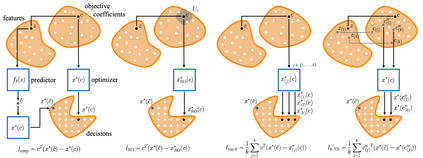
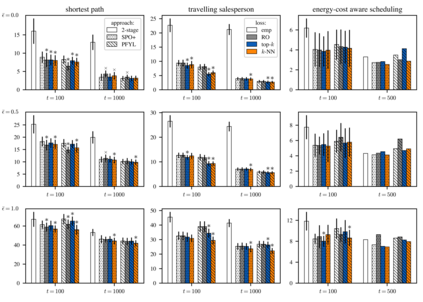
Optimization models used to make discrete decisions often contain uncertain parameters that are context-dependent and are estimated through prediction. To account for the quality of the decision made based on the prediction, decision-focused learning (end-to-end predict-then-optimize) aims at training the predictive model to minimize regret, i.e., the loss incurred by making a suboptimal decision. Despite the challenge of this loss function being possibly non-convex and in general non-differentiable, effective gradient-based learning approaches have been proposed to minimize the expected loss, using the empirical loss as a surrogate. However, empirical regret can be an ineffective surrogate because the uncertainty in the optimization model makes the empirical regret unequal to the expected regret in expectation. To illustrate the impact of this inequality, we evaluate the effect of aleatoric and epistemic uncertainty on the accuracy of empirical regret as a surrogate. Next, we propose three robust loss functions that more closely approximate expected regret. Experimental results show that training two state-of-the-art decision-focused learning approaches using robust regret losses improves test-sample empirical regret in general while keeping computational time equivalent relative to the number of training epochs.
翻译:暂无翻译