
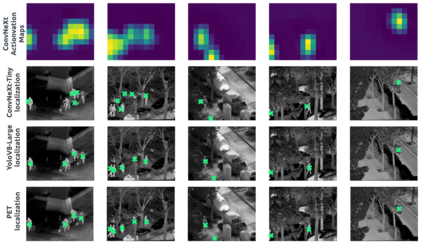
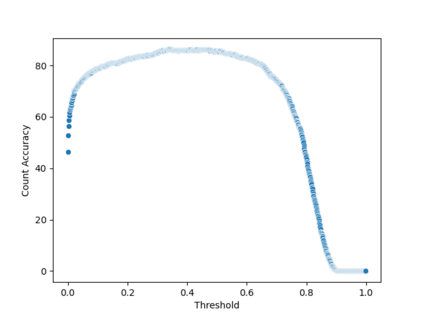
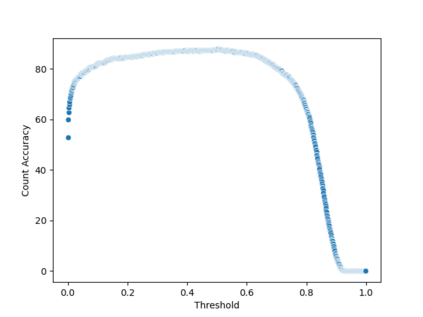
Object detection models are commonly used for people counting (and localization) in many applications but require a dataset with costly bounding box annotations for training. Given the importance of privacy in people counting, these models rely more and more on infrared images, making the task even harder. In this paper, we explore how weaker levels of supervision can affect the performance of deep person counting architectures for image classification and point-level localization. Our experiments indicate that counting people using a CNN Image-Level model achieves competitive results with YOLO detectors and point-level models, yet provides a higher frame rate and a similar amount of model parameters.
翻译:暂无翻译



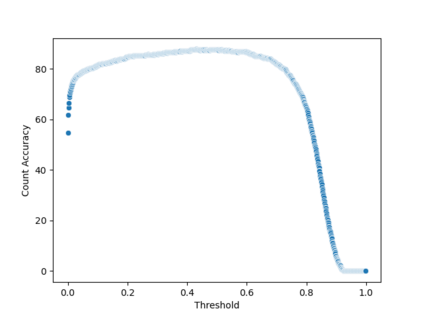
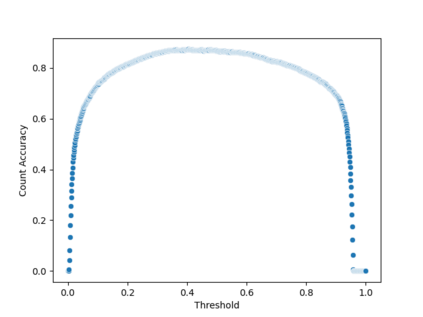
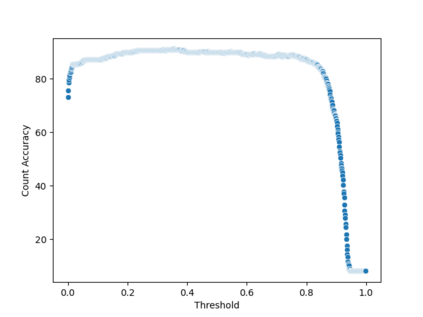
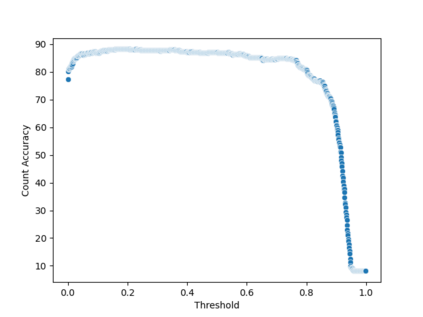
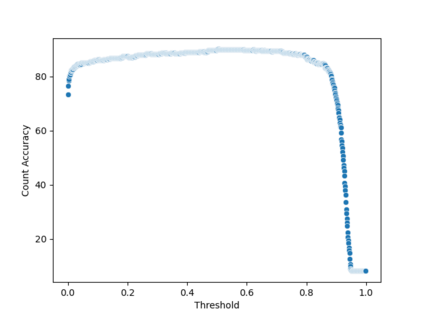









相关内容

ACM/IEEE第23届模型驱动工程语言和系统国际会议,是模型驱动软件和系统工程的首要会议系列,由ACM-SIGSOFT和IEEE-TCSE支持组织。自1998年以来,模型涵盖了建模的各个方面,从语言和方法到工具和应用程序。模特的参加者来自不同的背景,包括研究人员、学者、工程师和工业专业人士。MODELS 2019是一个论坛,参与者可以围绕建模和模型驱动的软件和系统交流前沿研究成果和创新实践经验。今年的版本将为建模社区提供进一步推进建模基础的机会,并在网络物理系统、嵌入式系统、社会技术系统、云计算、大数据、机器学习、安全、开源等新兴领域提出建模的创新应用以及可持续性。
官网链接:http://www.modelsconference.org/
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2024年1月10日
Arxiv
15+阅读 · 2021年1月21日



相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯