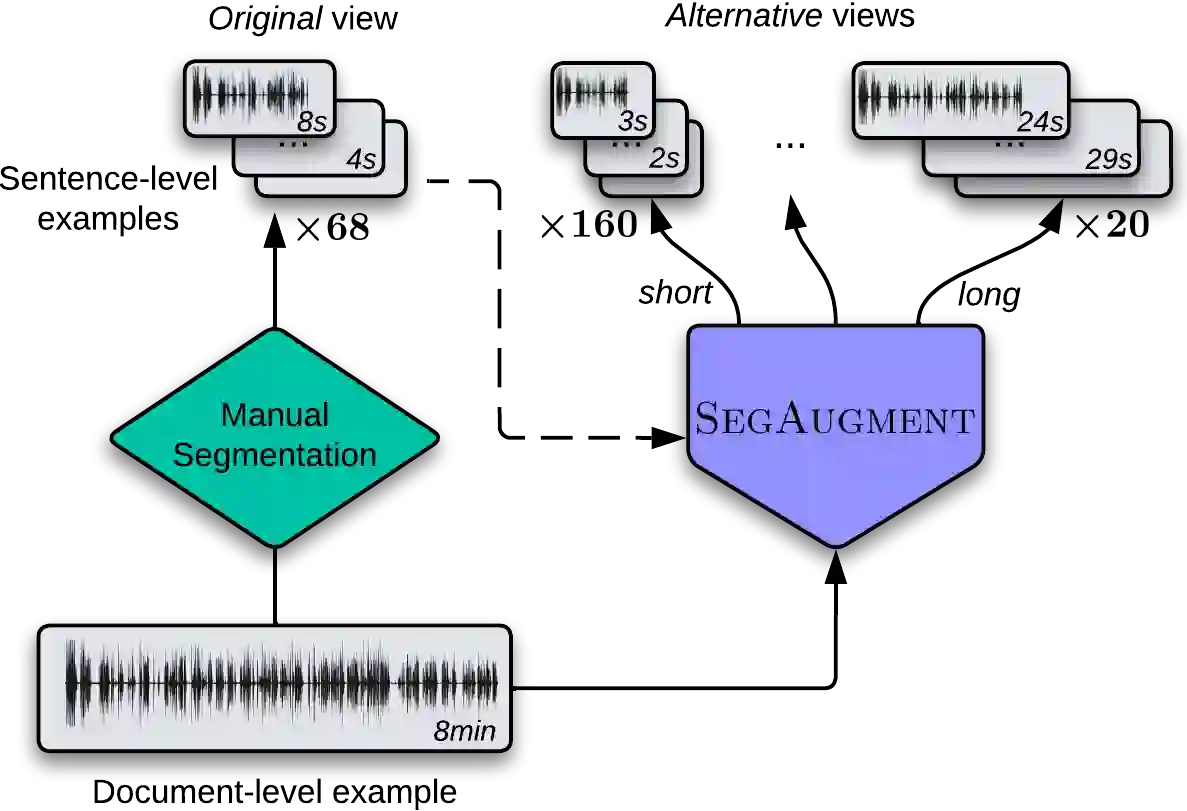
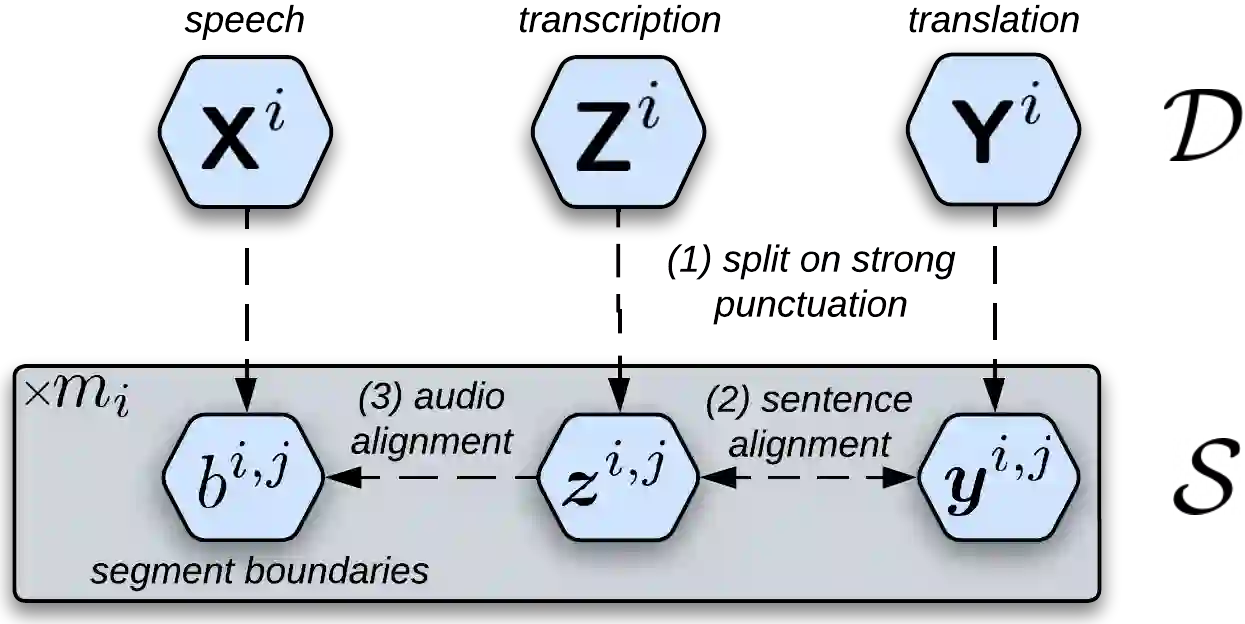
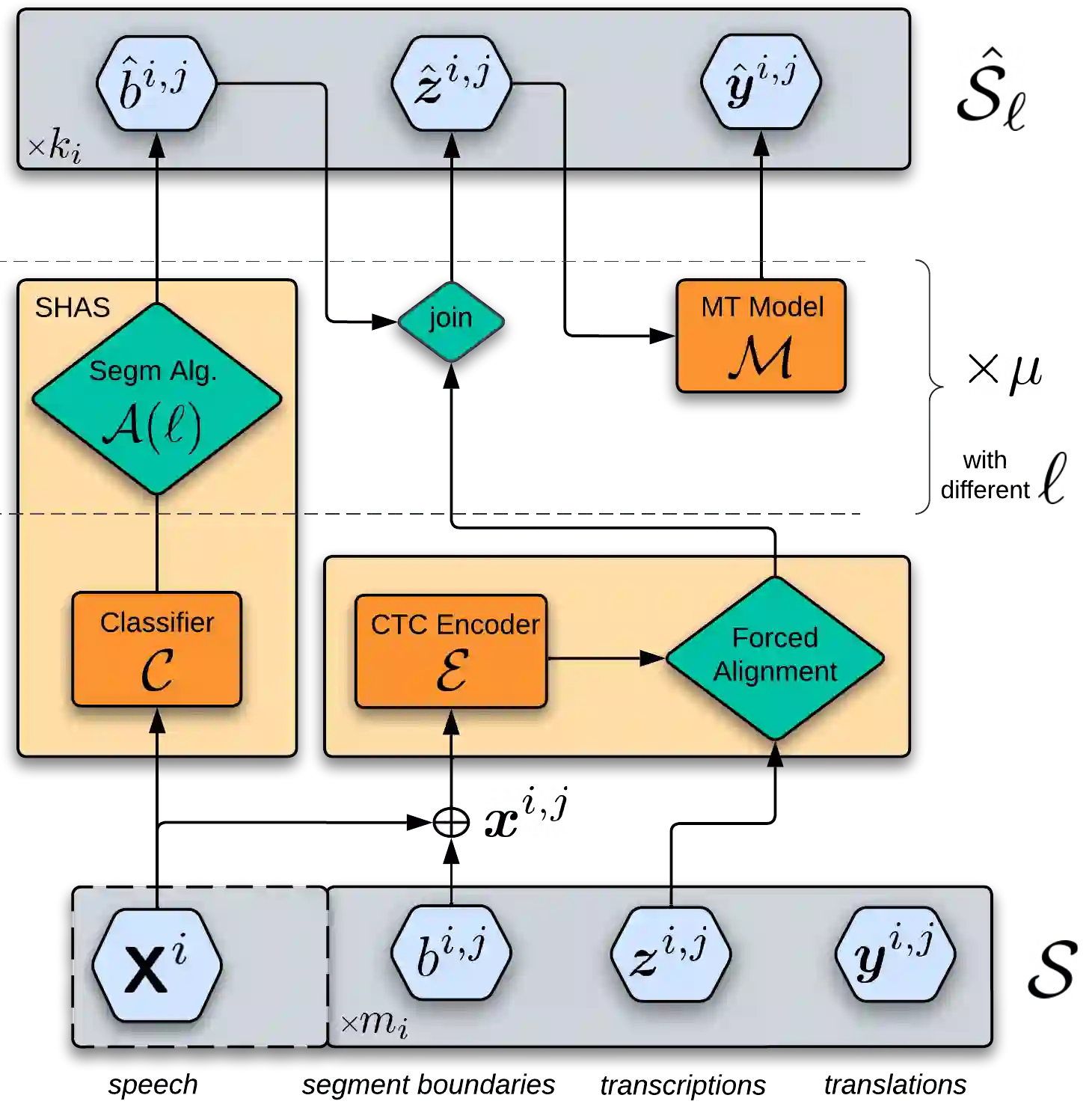
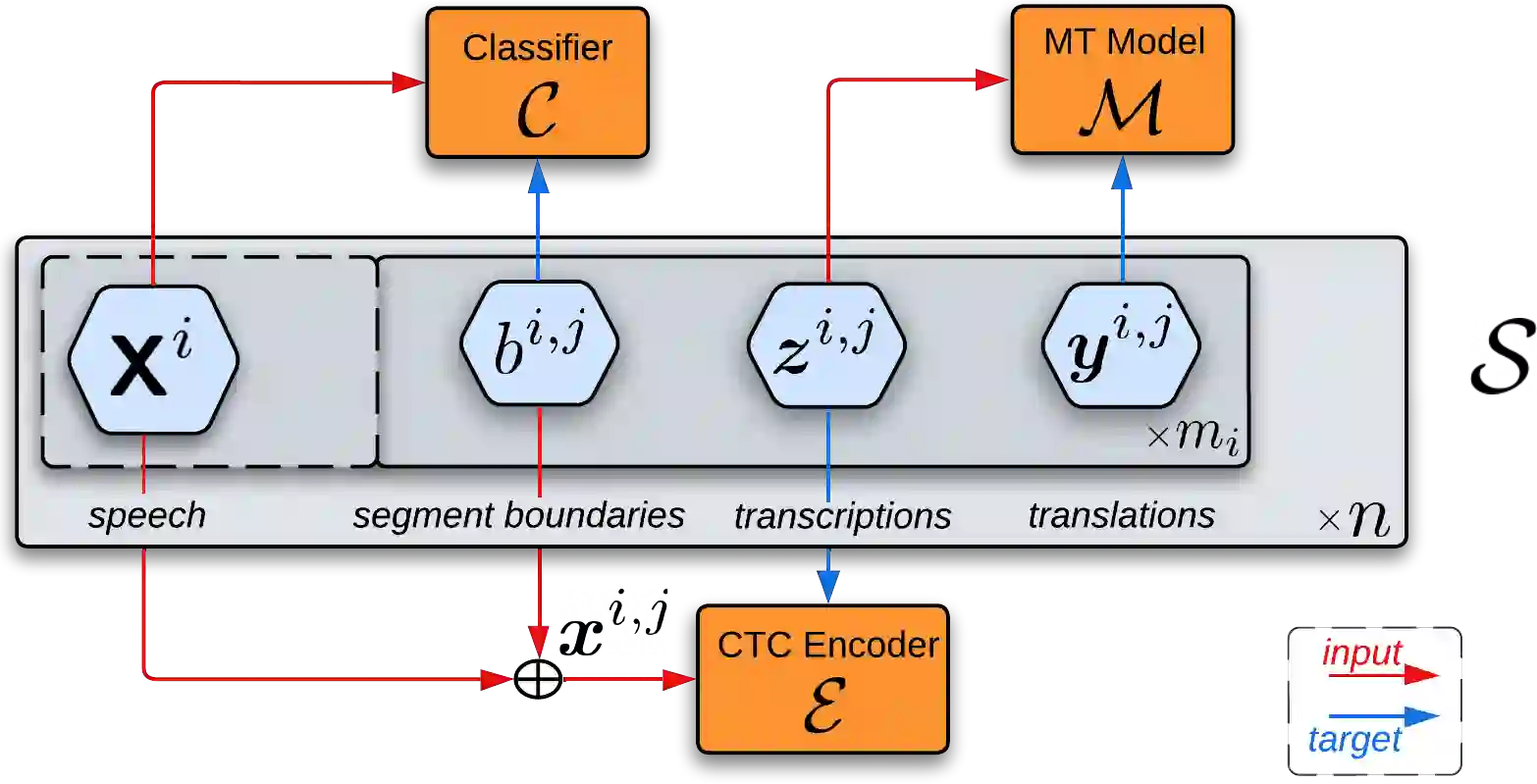
Data scarcity is one of the main issues with the end-to-end approach for Speech Translation, as compared to the cascaded one. Although most data resources for Speech Translation are originally document-level, they offer a sentence-level view, which can be directly used during training. But this sentence-level view is single and static, potentially limiting the utility of the data. Our proposed data augmentation method SegAugment challenges this idea and aims to increase data availability by providing multiple alternative sentence-level views of a dataset. Our method heavily relies on an Audio Segmentation system to re-segment the speech of each document, after which we obtain the target text with alignment methods. The Audio Segmentation system can be parameterized with different length constraints, thus giving us access to multiple and diverse sentence-level views for each document. Experiments in MuST-C show consistent gains across 8 language pairs, with an average increase of 2.2 BLEU points, and up to 4.7 BLEU for lower-resource scenarios in mTEDx. Additionally, we find that SegAugment is also applicable to purely sentence-level data, as in CoVoST, and that it enables Speech Translation models to completely close the gap between the gold and automatic segmentation at inference time.
翻译:与分级翻译相比,数据稀缺是语音翻译端到端方法的主要问题之一。虽然大部分语音翻译的数据资源最初是文件级,但它们提供了句级观点,可在培训期间直接使用。但这一句级观点是单一的,静态的,有可能限制数据的效用。我们提议的数据增强方法强化方法对这一想法提出了挑战,目的是通过提供数据集的多种替代判决级观点来增加数据的可用性。我们的方法在很大程度上依靠音频分解系统来重新组合每个文件的语音,然后我们用校正方法获得目标文本。音频分解系统可以用不同的长度限制参数进行参数化,从而使我们能够获得每个文件的多重和不同句级观点。 MuST-C的实验显示8对语言的一致收益,平均增加2.2 BLEU点,在mTEDx的低资源情景中达到4.7 BLEU。此外,我们发现Segament还适用于纯粹的句级数据,如COVST中的时间段和断断层之间那样,Segamentaltional transfer delationsideal supal suplegypeal delation amations in supturation in gyaltigration sal deal deal dequlturation supulation sulticulticulticulation。