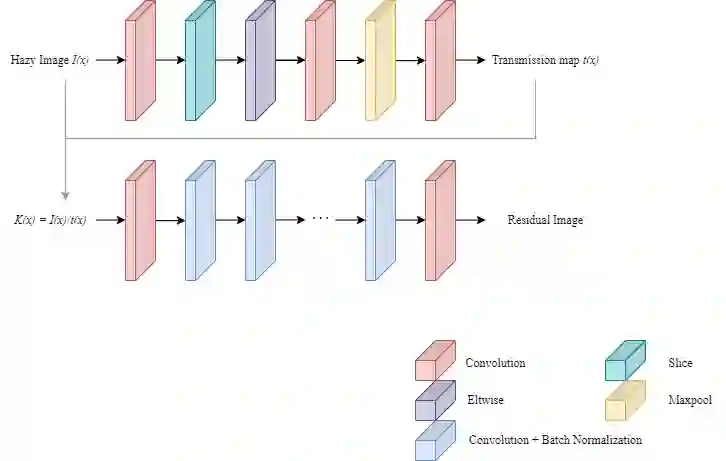
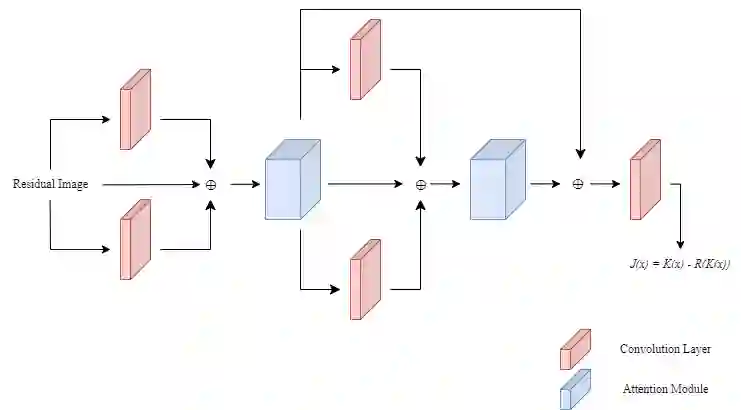
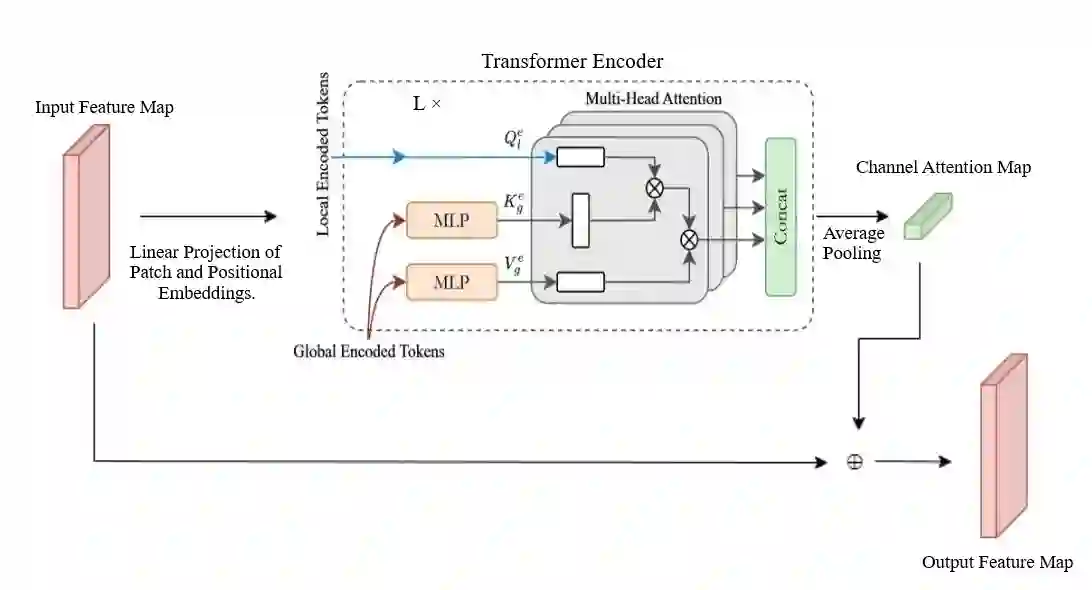
Images acquired in hazy conditions have degradations induced in them. Dehazing such images is a vexed and ill-posed problem. Scores of prior-based and learning-based approaches have been proposed to mitigate the effect of haze and generate haze-free images. Many conventional methods are constrained by their lack of awareness regarding scene depth and their incapacity to capture long-range dependencies. In this paper, a method that uses residual learning and vision transformers in an attention module is proposed. It essentially comprises two networks: In the first one, the network takes the ratio of a hazy image and the approximated transmission matrix to estimate a residual map. The second network takes this residual image as input and passes it through convolution layers before superposing it on the generated feature maps. It is then passed through global context and depth-aware transformer encoders to obtain channel attention. The attention module then infers the spatial attention map before generating the final haze-free image. Experimental results, including several quantitative metrics, demonstrate the efficiency and scalability of the suggested methodology.
翻译:暂无翻译