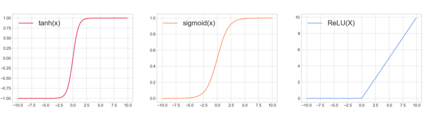
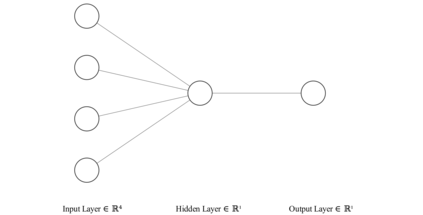
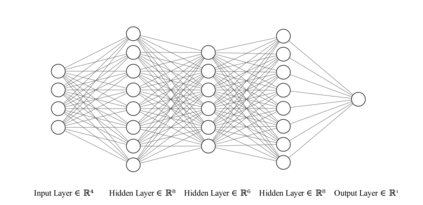
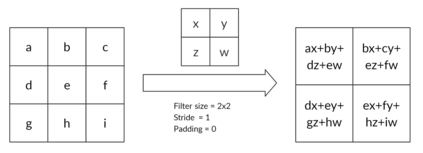
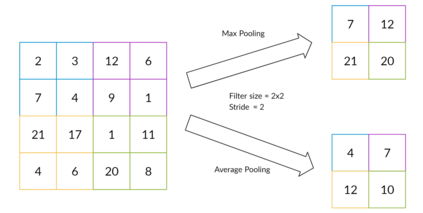
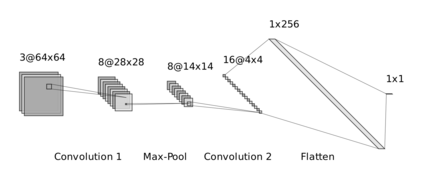
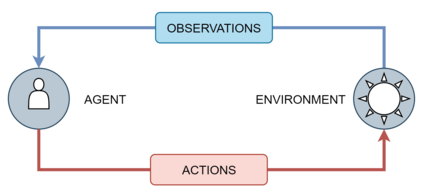
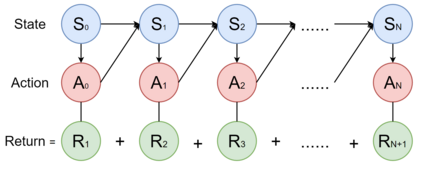
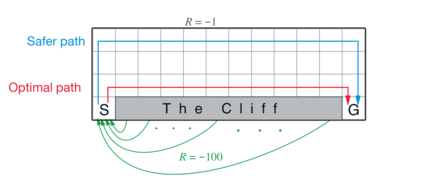
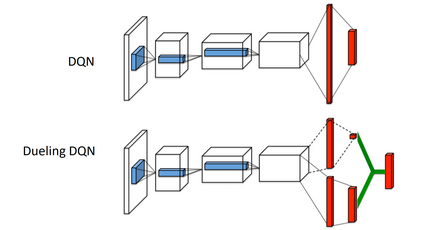
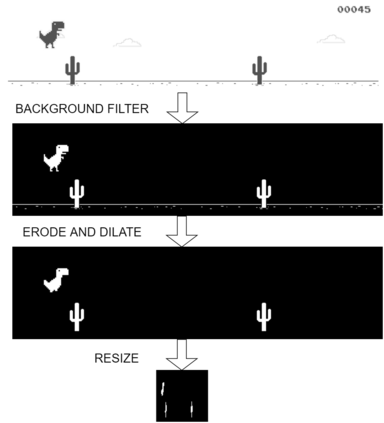
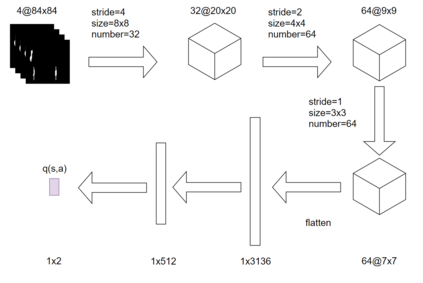
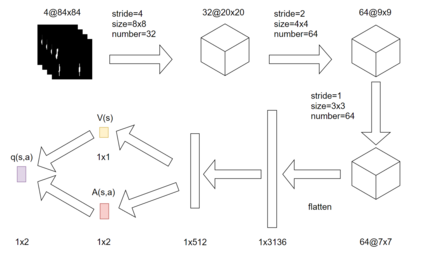
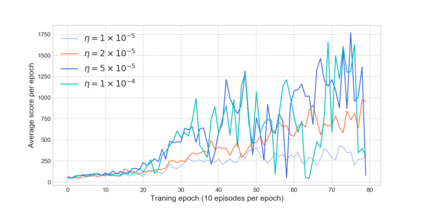
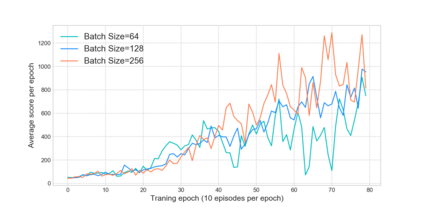
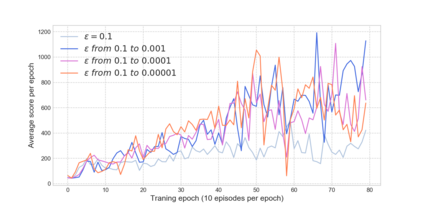
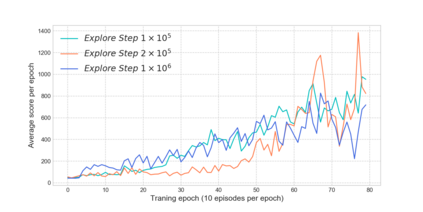
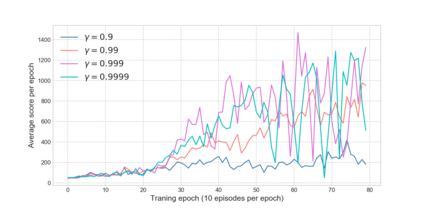
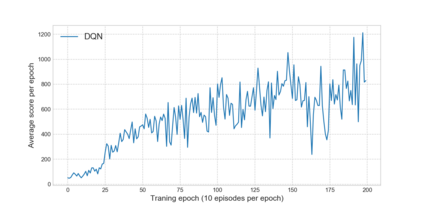
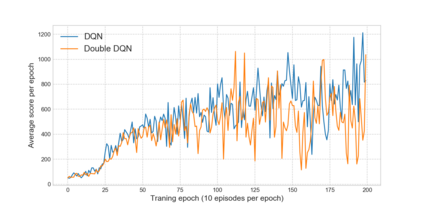
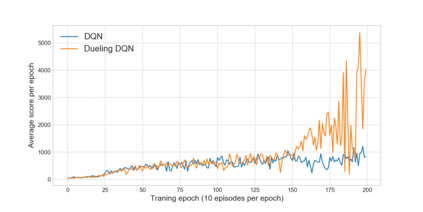
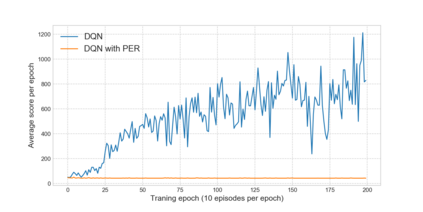
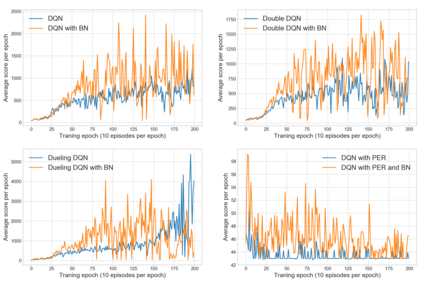
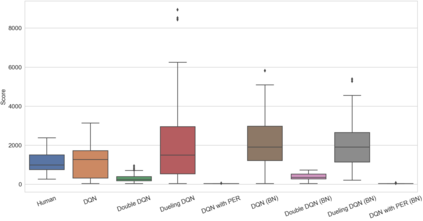
Reinforcement learning has exceeded human-level performance in game playing AI with deep learning methods according to the experiments from DeepMind on Go and Atari games. Deep learning solves high dimension input problems which stop the development of reinforcement for many years. This study uses both two techniques to create several agents with different algorithms that successfully learn to play T-rex Runner. Deep Q network algorithm and three types of improvements are implemented to train the agent. The results from some of them are far from satisfactory but others are better than human experts. Batch normalization is a method to solve internal covariate shift problems in deep neural network. The positive influence of this on reinforcement learning has also been proved in this study.
翻译:深层学习解决了高维输入问题,从而阻止了多年的加固开发。本研究使用两种技术来创造数个具有不同算法的代理商,这些算法成功地学会了玩T-rex Runner。为了培训代理商,实施了深Q网络算法和三种改进方法。其中一些方法的结果远远不能令人满意,但有些则比人类专家好。批量正常化是解决深神经网络内部共变换问题的一种方法。这项研究也证明了这一方法对强化学习的积极影响。