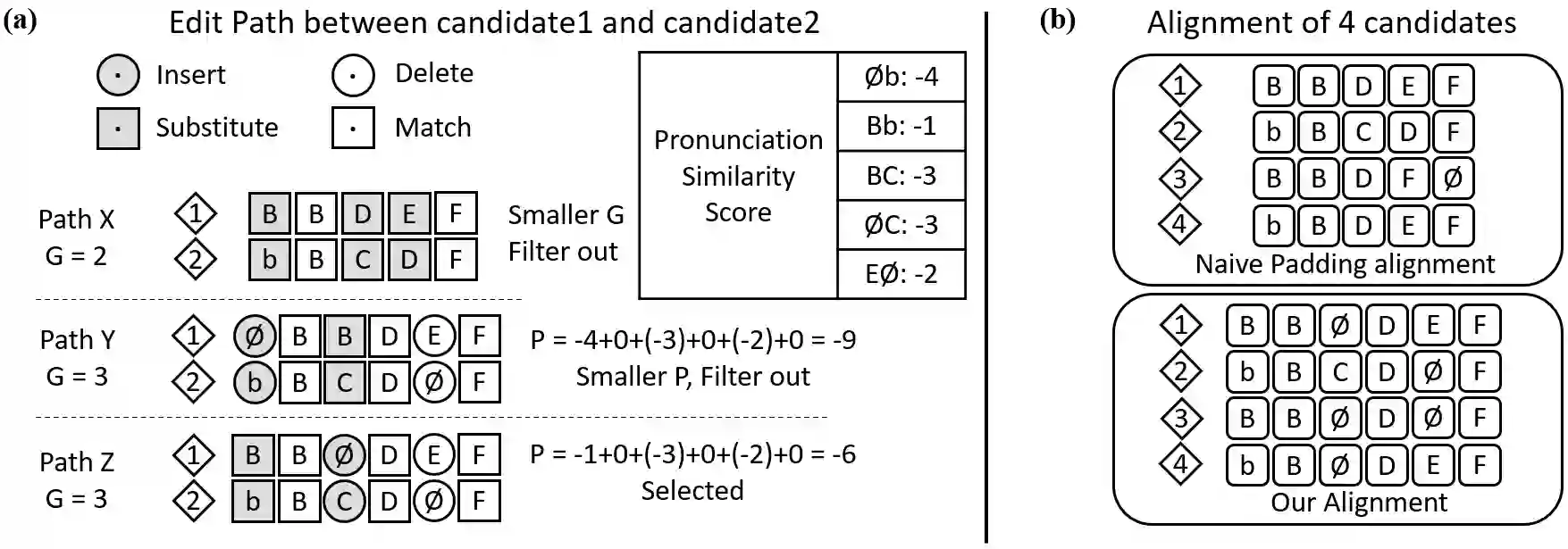
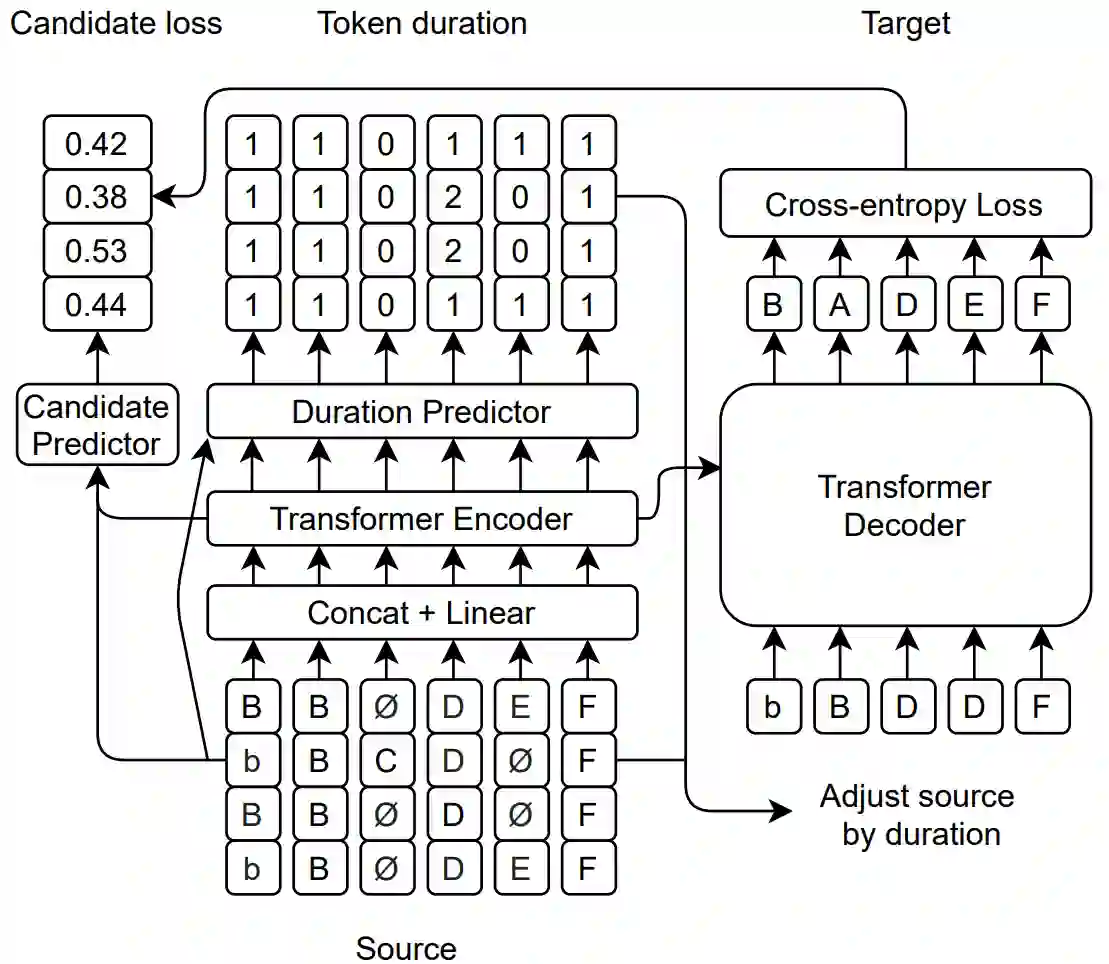
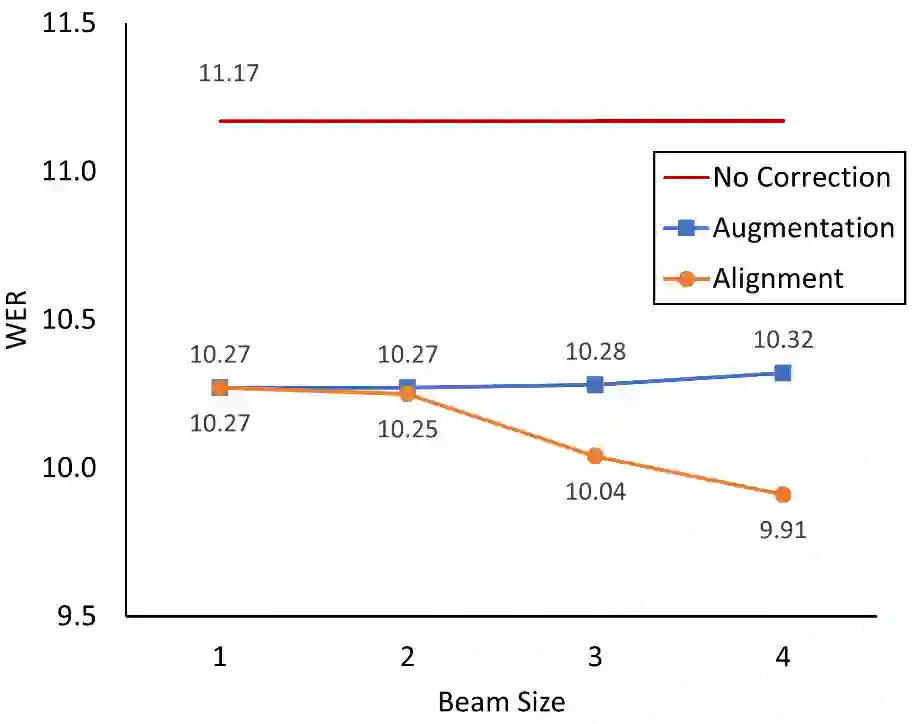
Error correction is widely used in automatic speech recognition (ASR) to post-process the generated sentence, and can further reduce the word error rate (WER). Although multiple candidates are generated by an ASR system through beam search, current error correction approaches can only correct one sentence at a time, failing to leverage the voting effect from multiple candidates to better detect and correct error tokens. In this work, we propose FastCorrect 2, an error correction model that takes multiple ASR candidates as input for better correction accuracy. FastCorrect 2 adopts non-autoregressive generation for fast inference, which consists of an encoder that processes multiple source sentences and a decoder that generates the target sentence in parallel from the adjusted source sentence, where the adjustment is based on the predicted duration of each source token. However, there are some issues when handling multiple source sentences. First, it is non-trivial to leverage the voting effect from multiple source sentences since they usually vary in length. Thus, we propose a novel alignment algorithm to maximize the degree of token alignment among multiple sentences in terms of token and pronunciation similarity. Second, the decoder can only take one adjusted source sentence as input, while there are multiple source sentences. Thus, we develop a candidate predictor to detect the most suitable candidate for the decoder. Experiments on our inhouse dataset and AISHELL-1 show that FastCorrect 2 can further reduce the WER over the previous correction model with single candidate by 3.2% and 2.6%, demonstrating the effectiveness of leveraging multiple candidates in ASR error correction. FastCorrect 2 achieves better performance than the cascaded re-scoring and correction pipeline and can serve as a unified post-processing module for ASR.
翻译:在自动语音识别(ASR)后处理生成的句子时广泛使用错误校正(ASR),这可以进一步降低字错误率(WER)。虽然多个候选人是通过ASR系统通过光搜索生成的,但当前错误校正方法只能一次纠正一个句子,无法从多个候选人中利用表决效应更好地检测和纠正错误符号。在这项工作中,我们建议快速更正2,一个将多个 ASR 候选人作为改进校正准确度的输入的错误校正模式。快速更正2,采用非自动递校制生成快速推断,包括一个编码器,处理多源句子和解码器,从调整源句的句子中平行生成目标句子。但目前的错误校正方法只能根据每个源符号的预测时间长度来纠正一个句子。首先,我们建议采用新的校正校正校正算算算算算法,使多个句子的代号一致程度最大化。第二, decoder 只能用一个校正的源代码来测试一个校正的版本,而我们只能用一个校正的版本来测试一个校正版本版本的版本的版本。