
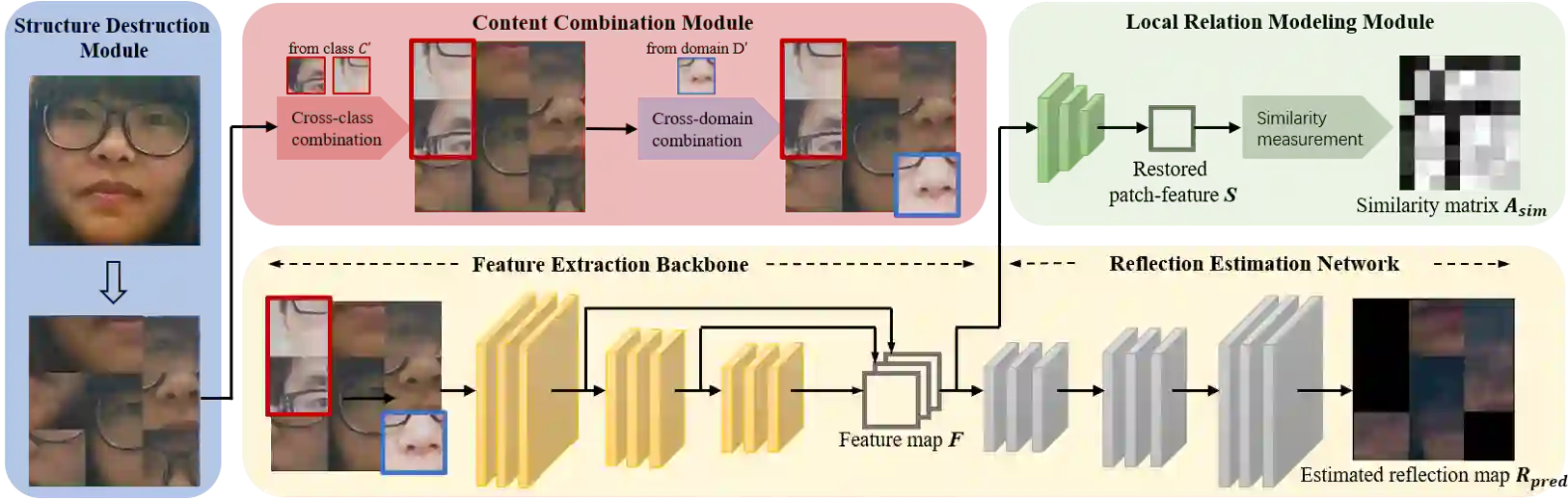
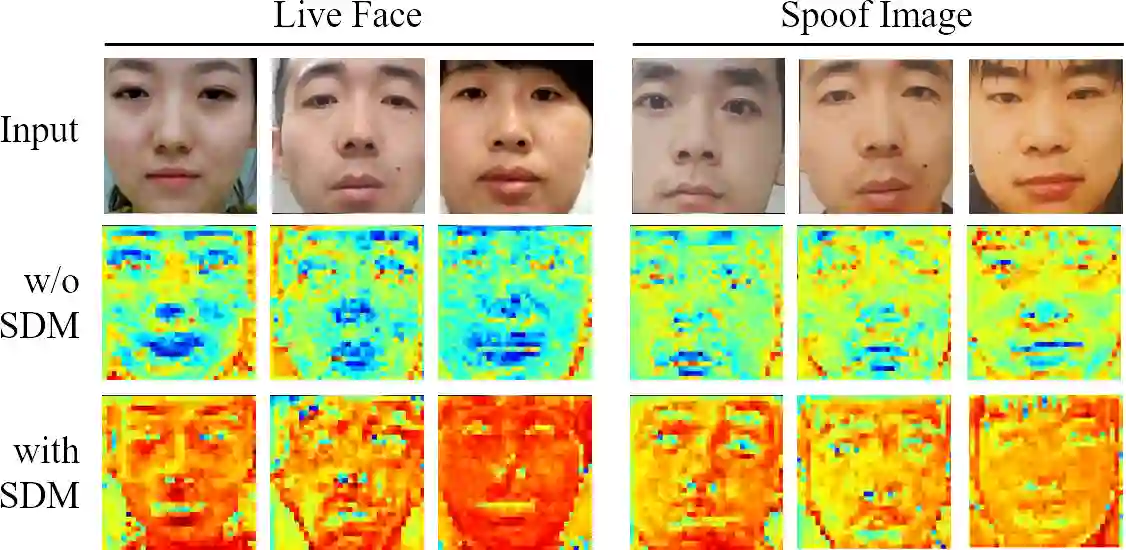
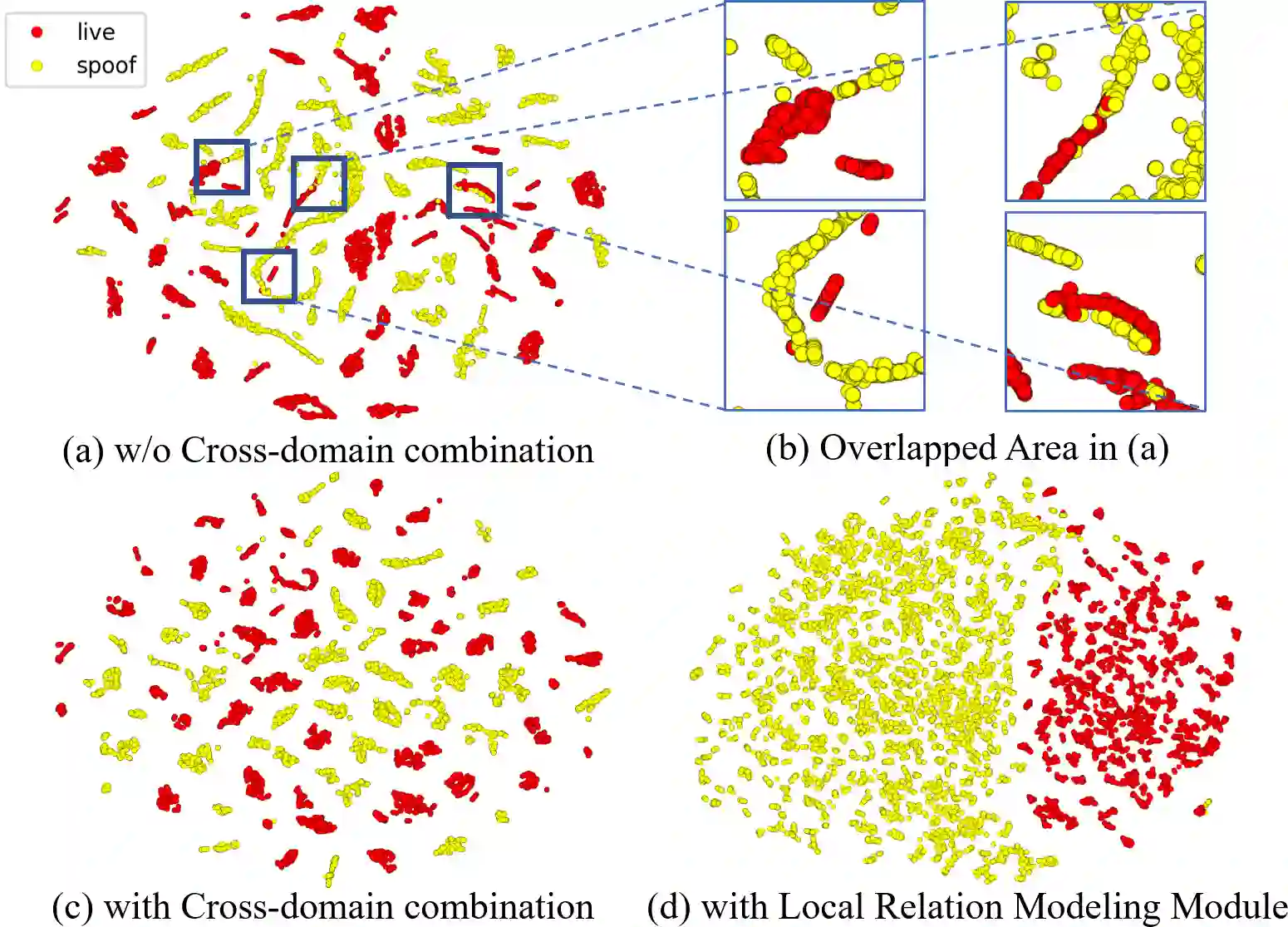
In pursuit of consolidating the face verification systems, prior face anti-spoofing studies excavate the hidden cues in original images to discriminate real persons and diverse attack types with the assistance of auxiliary supervision. However, limited by the following two inherent disturbances in their training process: 1) Complete facial structure in a single image. 2) Implicit subdomains in the whole dataset, these methods are prone to stick on memorization of the entire training dataset and show sensitivity to nonhomologous domain distribution. In this paper, we propose Structure Destruction Module and Content Combination Module to address these two imitations separately. The former mechanism destroys images into patches to construct a non-structural input, while the latter mechanism recombines patches from different subdomains or classes into a mixup construct. Based on this splitting-and-splicing operation, Local Relation Modeling Module is further proposed to model the second-order relationship between patches. We evaluate our method on extensive public datasets and promising experimental results to demonstrate the reliability of our method against state-of-the-art competitors.
翻译:在巩固面部核查系统的过程中,先面面部反渗透研究挖掘了原始图像中隐藏的线索,在辅助监督的协助下歧视真实人和不同攻击类型,但受培训过程中以下两种内在干扰的限制:(1) 单一图像中的完整面部结构;(2) 整个数据集中隐含的子域,这些方法容易坚持整个培训数据集的记忆化,并显示对非混合域分布的敏感性;在本文件中,我们提议结构销毁模块和内容合并模块分别处理这两个模仿。旧机制将图像摧毁为补丁,以构建非结构输入,而后一种机制的补丁则从不同子域或类进行补丁,形成混合结构。根据这种分裂和混合操作,进一步提议地方关系模型,以模拟补丁之间的第二顺序关系。我们评估了我们关于广泛的公共数据集的方法,并承诺实验结果,以证明我们的方法对处于状态的竞争对手的可靠性。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

