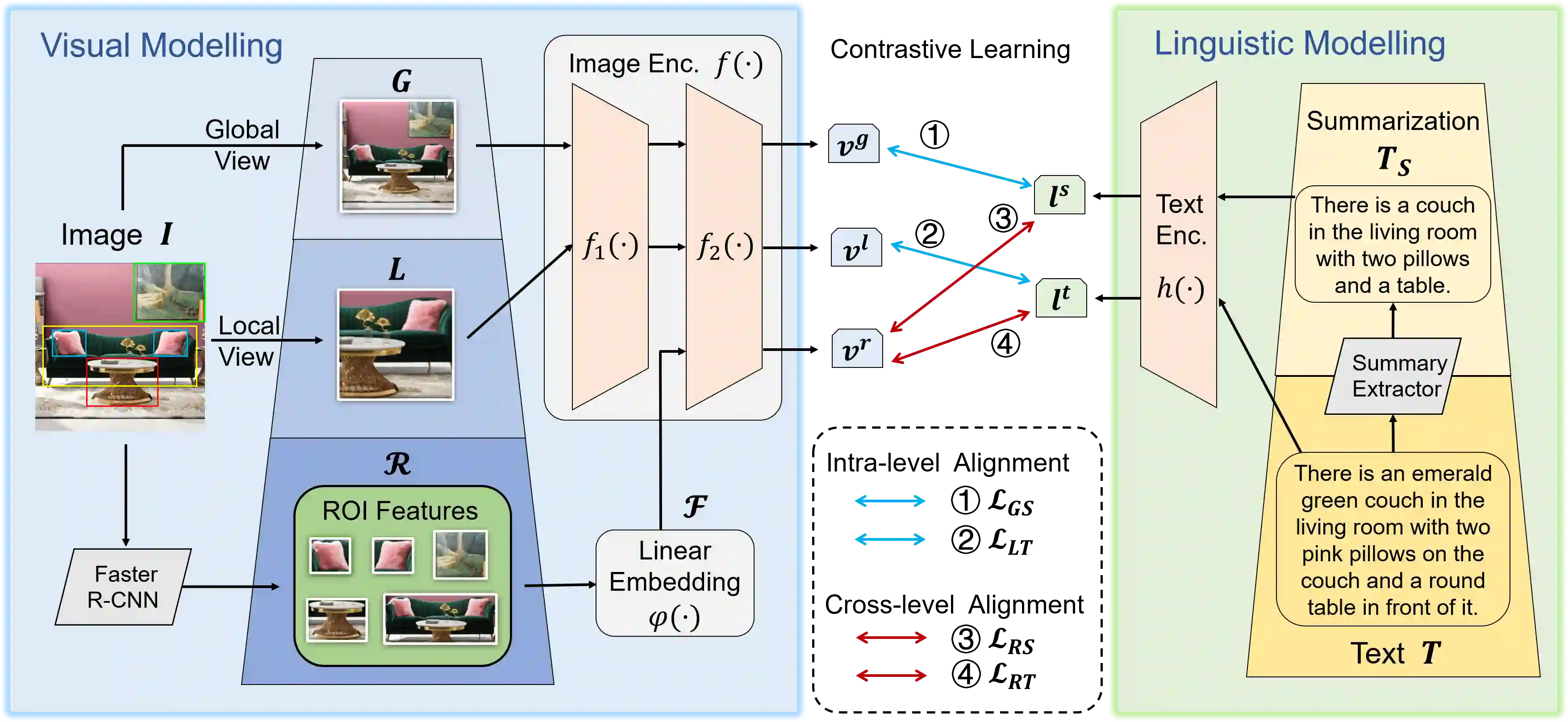
Large-scale vision-language pre-training has achieved promising results on downstream tasks. Existing methods highly rely on the assumption that the image-text pairs crawled from the Internet are in perfect one-to-one correspondence. However, in real scenarios, this assumption can be difficult to hold: the text description, obtained by crawling the affiliated metadata of the image, often suffer from semantic mismatch and mutual compatibility. To address these issues, here we introduce PyramidCLIP, which constructs an input pyramid with different semantic levels, and aligns visual elements and linguistic elements in the form of hierarchy via intra-level semantics alignment and cross-level relation alignment. Furthermore, we adjust the objective function by softening the loss of negative samples (unpaired samples) so as to weaken the strict constraint during the pre-training stage, thus mitigating the risk of the model being over-confident. Experiments on three downstream tasks, including zero-shot image classification, zero-shot image-text retrieval and image object detection, verify the effectiveness of the proposed PyramidCLIP. In particular, with the same amount of pre-training data of 15 millions image-text pairs, PyramidCLIP exceeds CLIP by 19.2%/18.5%/19.6% respectively, with the image encoder being ResNet-50/ViT-B32/ViT-B16 on ImageNet zero-shot classification top-1 accuracy. When scaling to larger datasets, the results of PyramidCLIP only trained for 8 epochs using 128M image-text pairs are very close to that of CLIP trained for 32 epochs using 400M training data.
翻译:大型视觉语言前培训在下游任务上取得了令人乐观的成果。 现有方法高度依赖以下假设:从互联网上爬出的图像文本对对配是完美的一对对对应。 然而,在真实情况下,这一假设可能难以坚持:通过爬上附属图像元数据获得的文本描述,往往受到语义不匹配和相互兼容的影响。 为解决这些问题,我们在这里引入了PyrammidCLIP,它构建了一个具有不同语义级别的输入金字塔,并且通过内部语义对齐和跨级别关系对齐,将更大的视觉元素和语言元素以等级形式对齐。此外,我们调整目标功能,通过软化负面样本的丢失(未配置样本)来降低培训前阶段的严格限制,从而减轻模型过于自信的风险。 实验了三项下游任务,包括零发图像分类、零发图像检索时缩放图像文本和图像对象检测,核查拟议的PyrammidCLIP的更大视觉元素和语言元素结构。 具体来说,使用经过培训的CLMLM 5 高级数据数量相同,使用经过培训的CLLV 5 的CLR 的CL5 的CL5- 的CRVIP- 10 的高级数据,使用经过训练的CR5的C- 的C- 的C- 5的C- RVIP- 5 5 的C- 的升级的升级的C- 5 5 的S- 5 的S- Rest的高级图像数据。