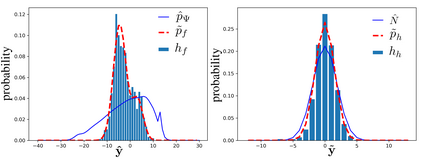
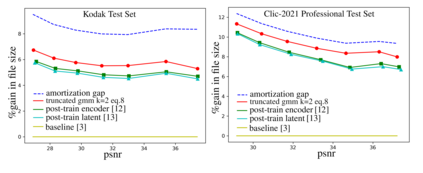
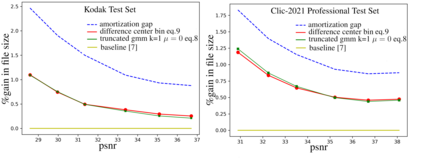
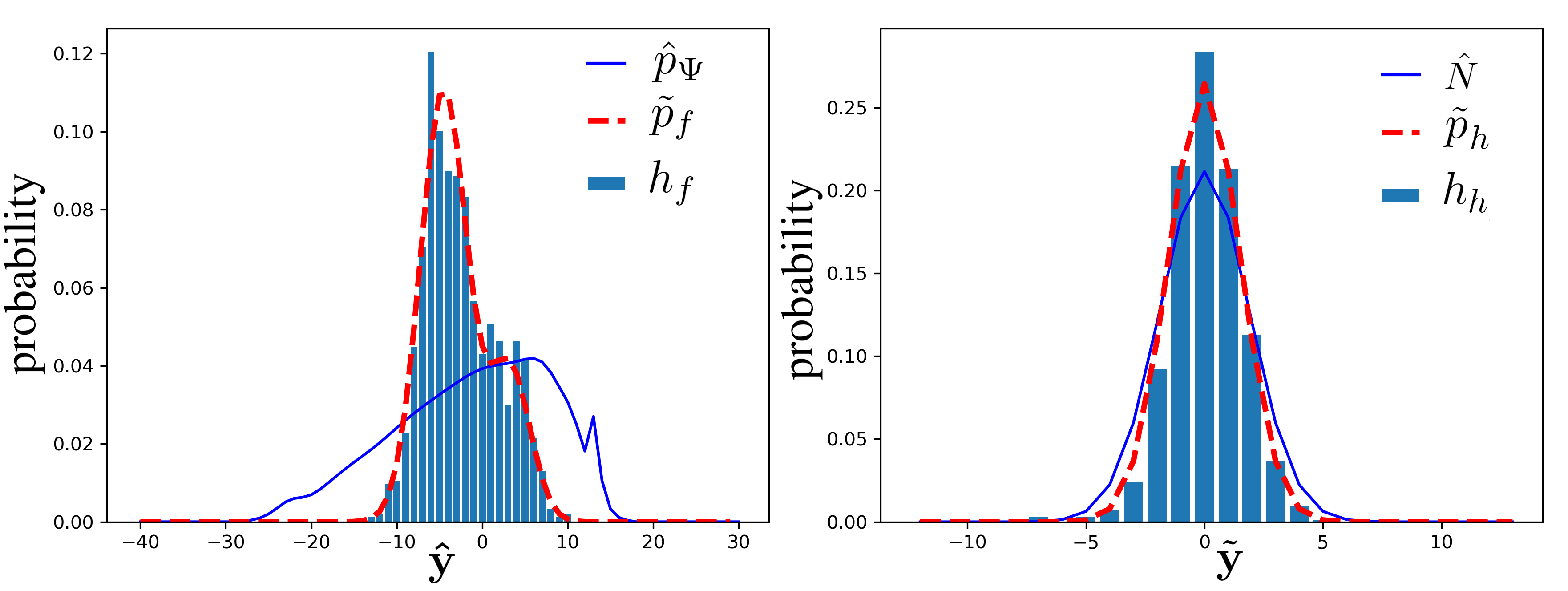
End-to-end deep trainable models are about to exceed the performance of the traditional handcrafted compression techniques on videos and images. The core idea is to learn a non-linear transformation, modeled as a deep neural network, mapping input image into latent space, jointly with an entropy model of the latent distribution. The decoder is also learned as a deep trainable network, and the reconstructed image measures the distortion. These methods enforce the latent to follow some prior distributions. Since these priors are learned by optimization over the entire training set, the performance is optimal in average. However, it cannot fit exactly on every single new instance, hence damaging the compression performance by enlarging the bit-stream. In this paper, we propose a simple yet efficient instance-based parameterization method to reduce this amortization gap at a minor cost. The proposed method is applicable to any end-to-end compressing methods, improving the compression bitrate by 1% without any impact on the reconstruction quality.
翻译:端到端深的可训练模型即将超过传统手工制作的视频和图像压缩技术的性能。 核心理念是学习非线性转换, 以深神经网络为模型, 将输入图像映射到潜空间, 并配有潜值分布的加密模型 。 解码器也以深可训练的网络学习, 重建后的图像测量扭曲。 这些方法强制潜值跟踪某些先前的分布。 由于这些前缀是通过优化整个训练集而学习的, 平均性能是最佳的。 但是, 它不能完全适应于每一个单一的新实例, 从而通过扩大比特流破坏压缩性能。 在本文中, 我们提出了一个简单而高效的基于实例的参数化方法, 以较低的成本缩小这个摊余差距 。 提议的方法适用于任何端到端的压缩法, 在不影响重建质量的情况下, 将压缩位速率提高1% 。