
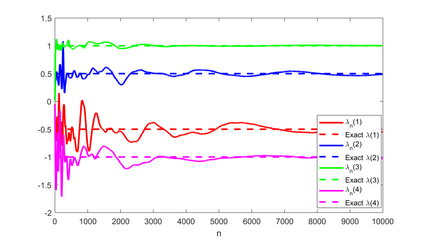
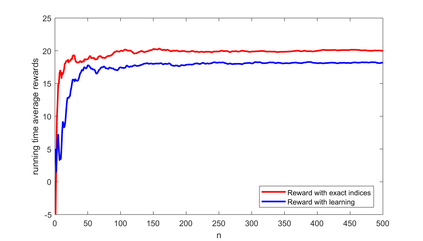
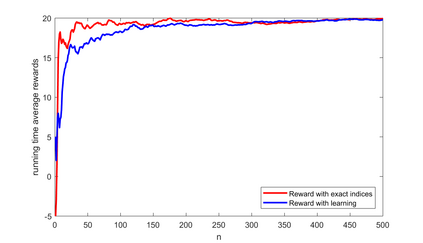
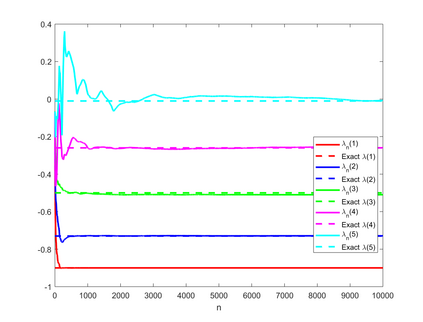
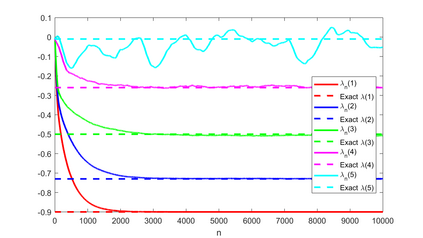
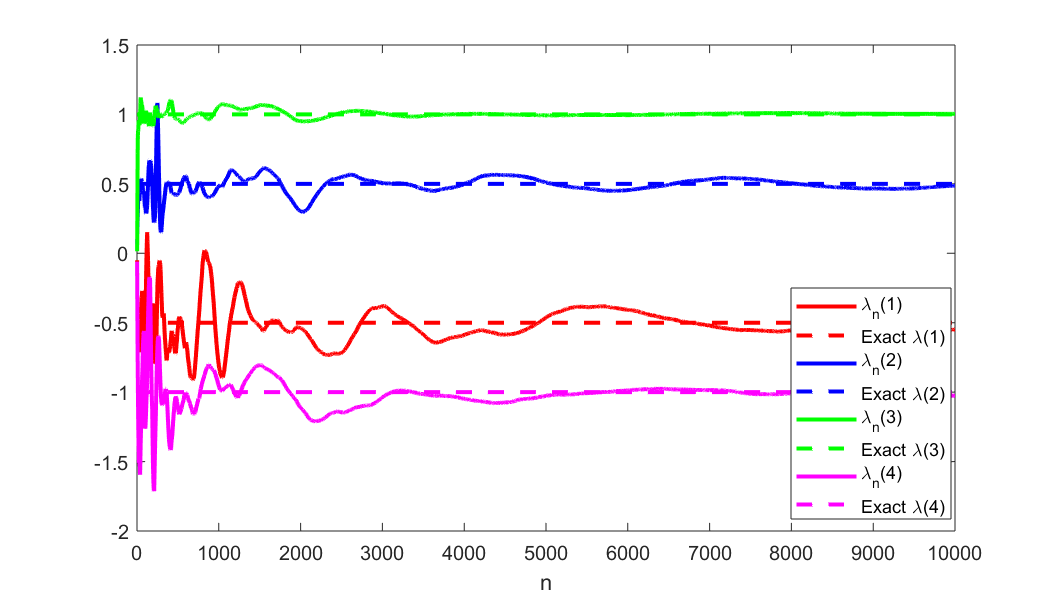
A novel reinforcement learning algorithm is introduced for multiarmed restless bandits with average reward, using the paradigms of Q-learning and Whittle index. Specifically, we leverage the structure of the Whittle index policy to reduce the search space of Q-learning, resulting in major computational gains. Rigorous convergence analysis is provided, supported by numerical experiments. The numerical experiments show excellent empirical performance of the proposed scheme.
翻译:利用Q-学习和Whittle指数的范例,为多武装无休眠强盗引入了新的强化学习算法,并给予平均回报。 具体地说,我们利用Whittle指数政策的结构来减少Q-学习的搜索空间,从而带来重大的计算收益。 在数字实验的支持下,提供了严格的趋同分析。 数字实验显示了拟议计划的良好实证表现。
相关内容

Arxiv
5+阅读 · 2020年4月2日
Arxiv
4+阅读 · 2018年4月22日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2020年4月2日
Arxiv
4+阅读 · 2018年4月22日