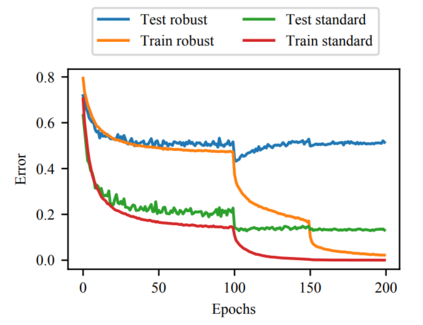
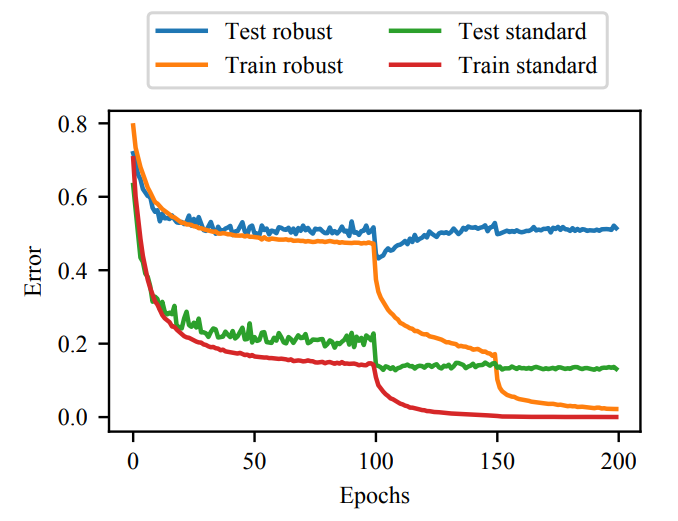
Adversarial training is a widely used method to improve the robustness of deep neural networks (DNNs) over adversarial perturbations. However, it is empirically observed that adversarial training on over-parameterized networks often suffers from the \textit{robust overfitting}: it can achieve almost zero adversarial training error while the robust generalization performance is not promising. In this paper, we provide a theoretical understanding of the question of whether overfitted DNNs in adversarial training can generalize from an approximation viewpoint. Specifically, our main results are summarized into three folds: i) For classification, we prove by construction the existence of infinitely many adversarial training classifiers on over-parameterized DNNs that obtain arbitrarily small adversarial training error (overfitting), whereas achieving good robust generalization error under certain conditions concerning the data quality, well separated, and perturbation level. ii) Linear over-parameterization (meaning that the number of parameters is only slightly larger than the sample size) is enough to ensure such existence if the target function is smooth enough. iii) For regression, our results demonstrate that there also exist infinitely many overfitted DNNs with linear over-parameterization in adversarial training that can achieve almost optimal rates of convergence for the standard generalization error. Overall, our analysis points out that robust overfitting can be avoided but the required model capacity will depend on the smoothness of the target function, while a robust generalization gap is inevitable. We hope our analysis will give a better understanding of the mathematical foundations of robustness in DNNs from an approximation view.
翻译:暂无翻译