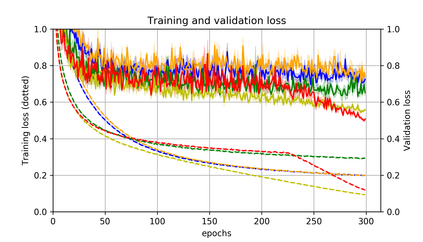
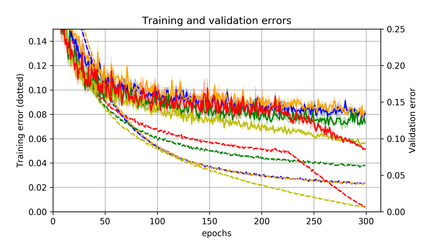
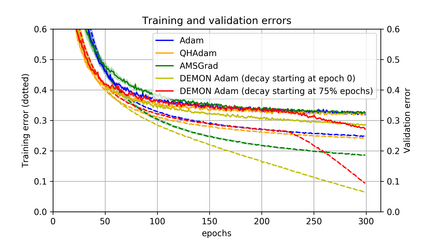
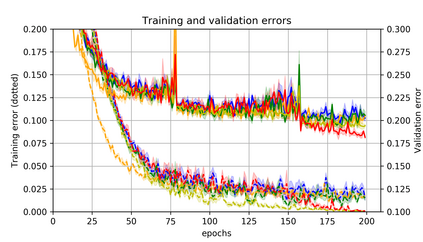
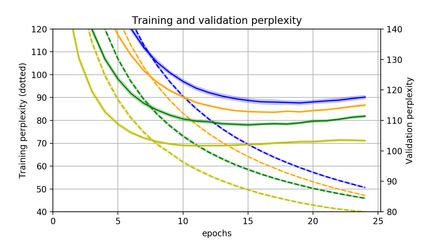
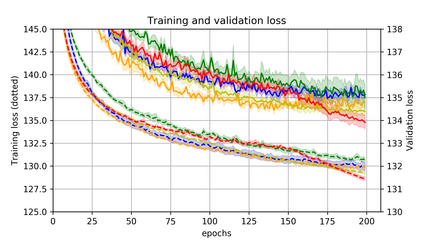
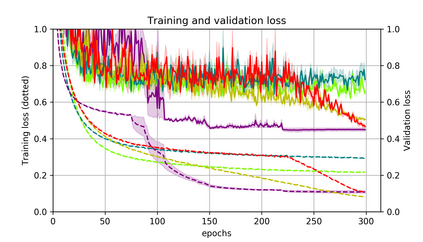
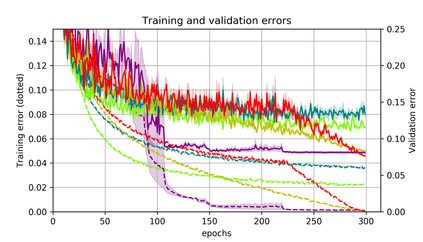
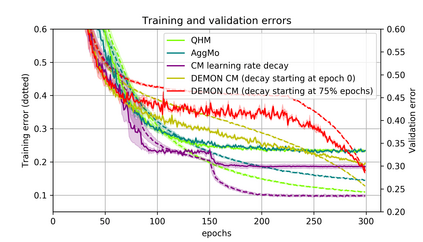
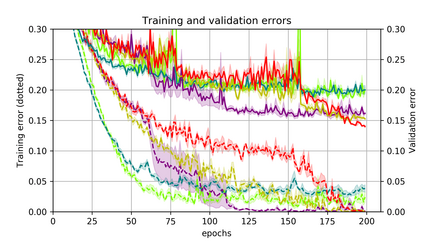
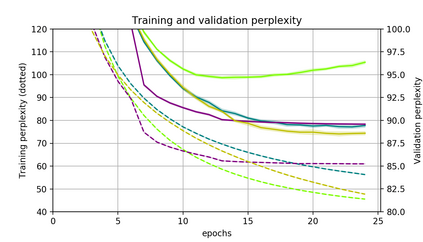
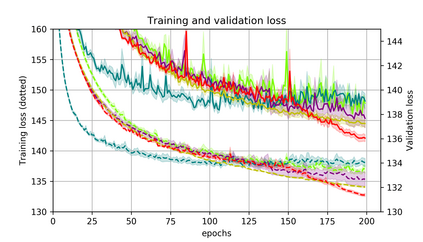
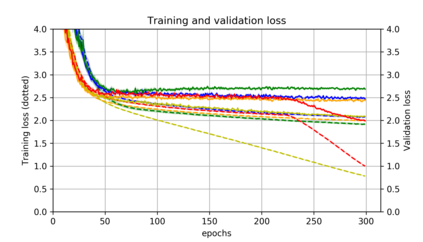
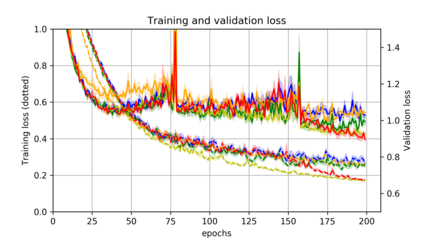
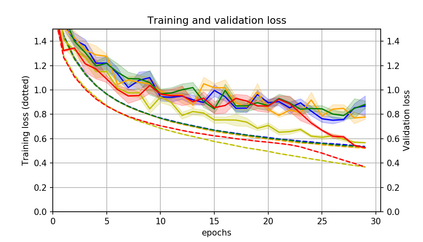
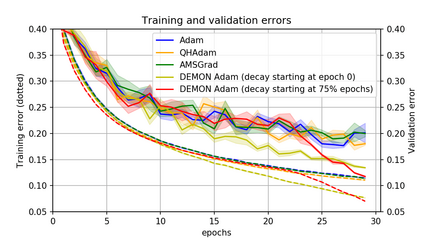
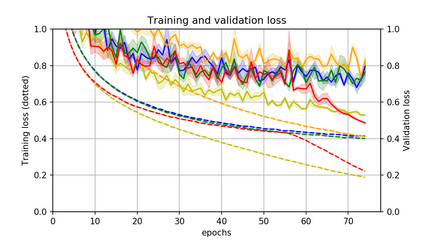
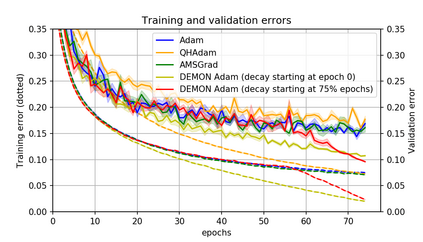
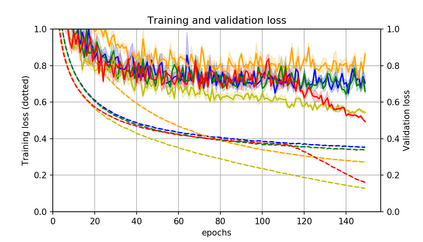
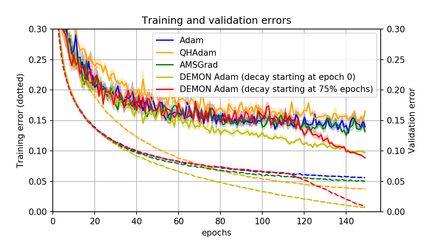
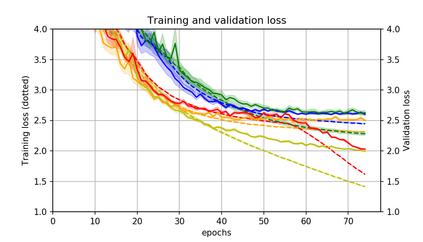
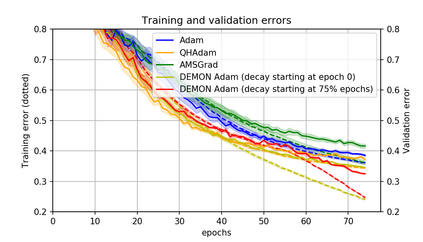
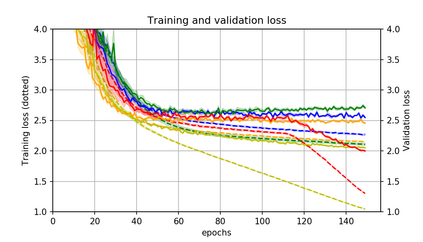
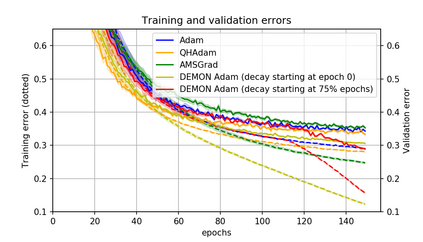
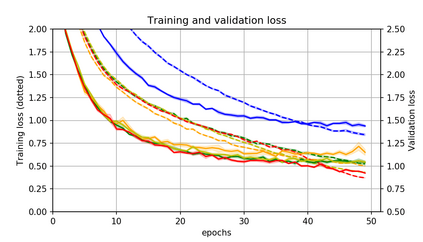
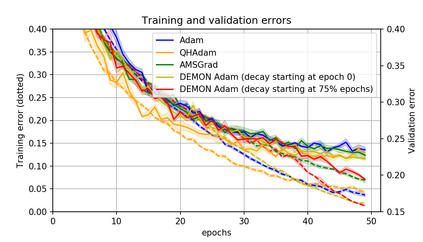
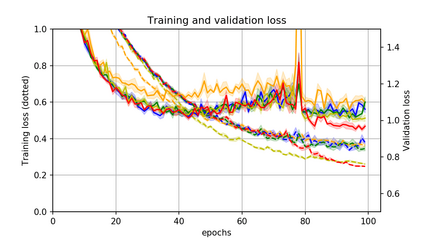
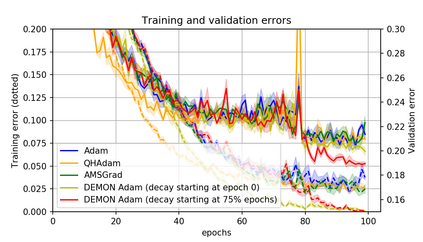
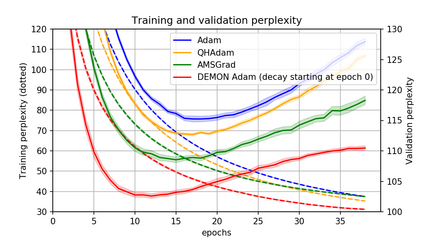
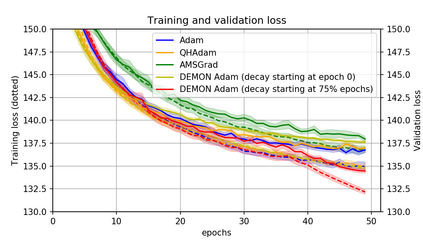
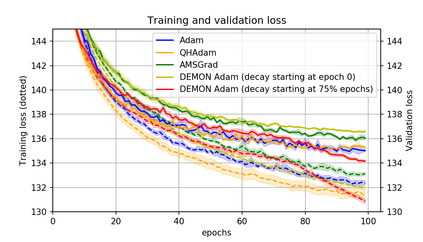
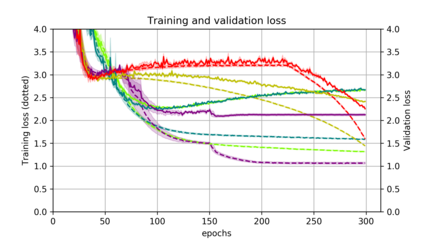
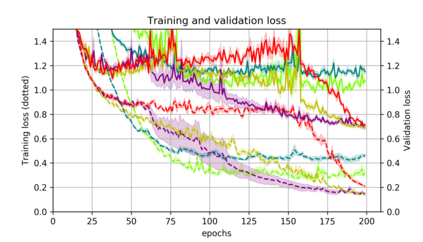
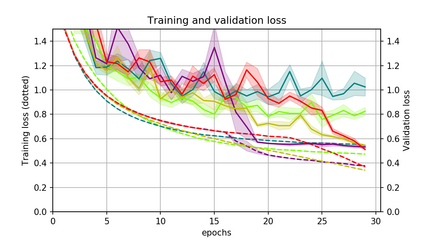
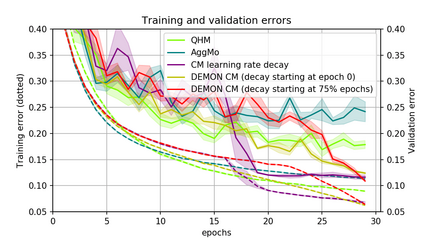
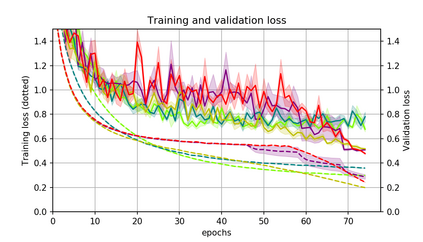
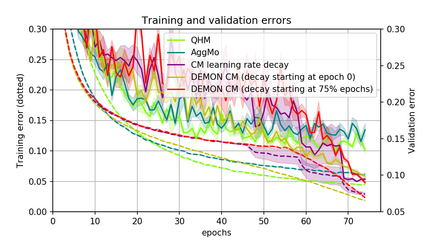
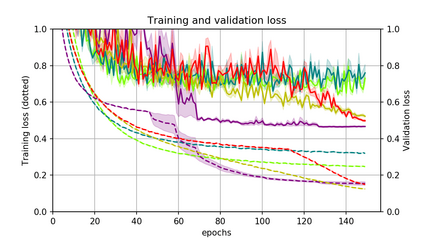
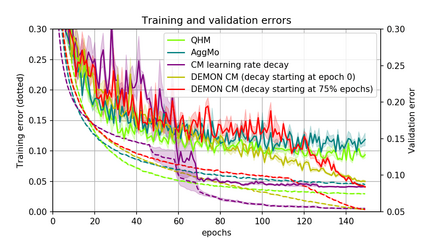
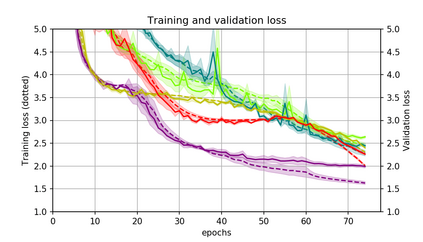
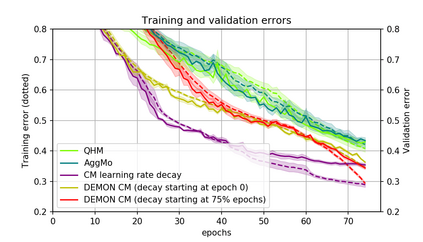
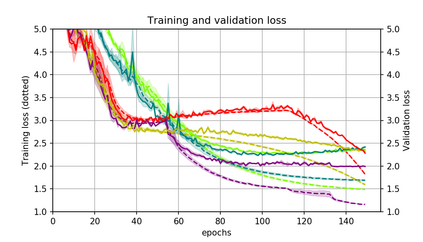
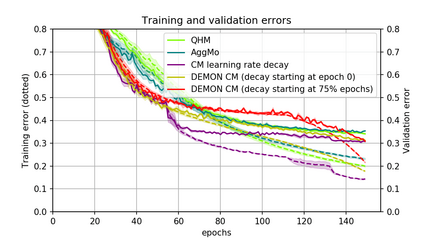
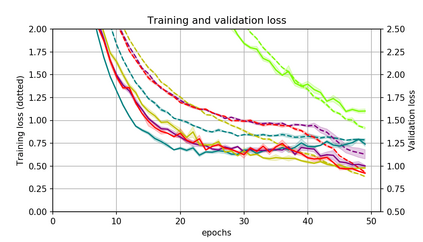
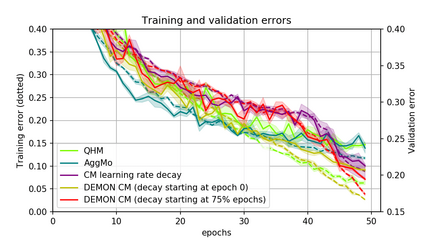
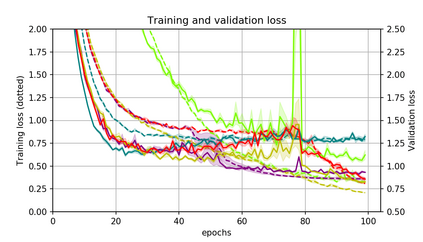
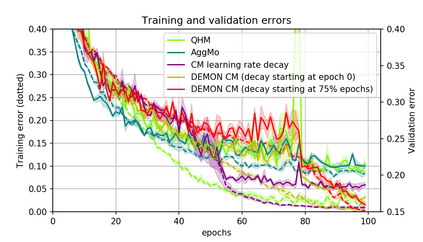
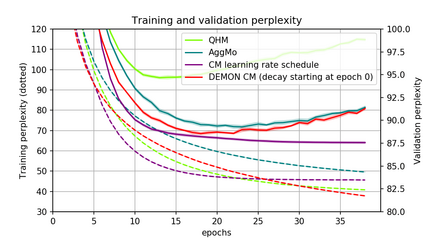
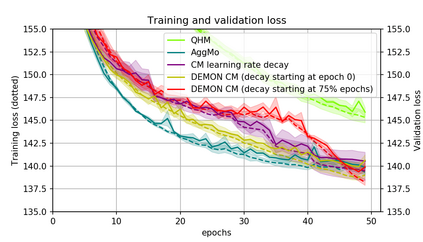
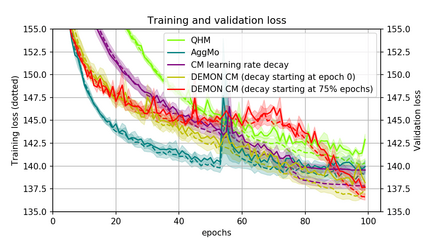
Momentum is a simple and popular technique in deep learning for gradient-based optimizers. We propose a decaying momentum (Demon) rule, motivated by decaying the total contribution of a gradient to all future updates. Applying Demon to Adam leads to significantly improved training, notably competitive to momentum SGD with learning rate decay, even in settings in which adaptive methods are typically non-competitive. Similarly, applying Demon to momentum SGD rivals momentum SGD with learning rate decay, and in many cases leads to improved performance. Demon is trivial to implement and incurs limited extra computational overhead, compared to the vanilla counterparts.
翻译:动力是梯度优化者深层学习中的一种简单而流行的技术。 我们提出了一个衰落的势头( 守护程序) 规则, 其动机是削弱梯度对未来所有更新的总贡献。 将恶魔应用于亚当可以大大改进培训, 特别是通过学习率衰减, 即使在适应方法通常不具竞争力的环境中, 尤其能通过学习率衰减获得SGD的动力。 同样, 将SGD与SGD势头相对应, 并在许多情况下导致学习率衰减, 导致性能的改善。 与香草对口方相比, 实施恶魔是微不足道的, 并且产生有限的计算性间接费用。