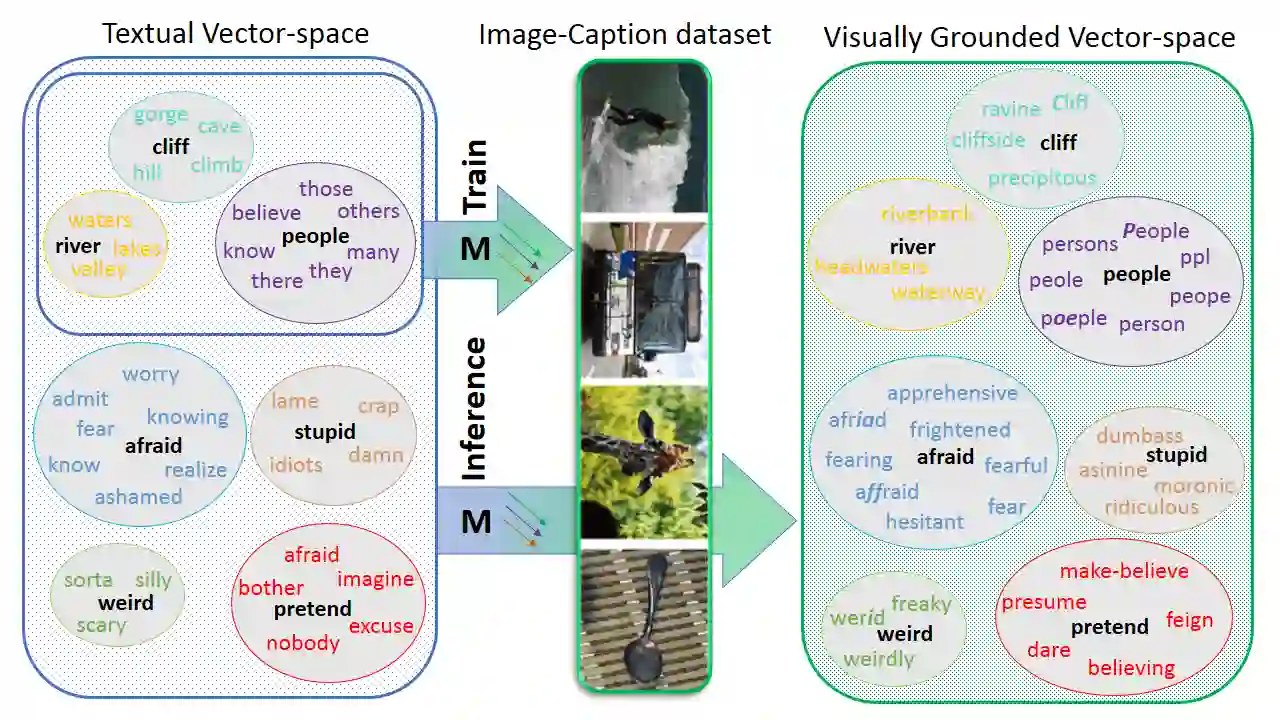
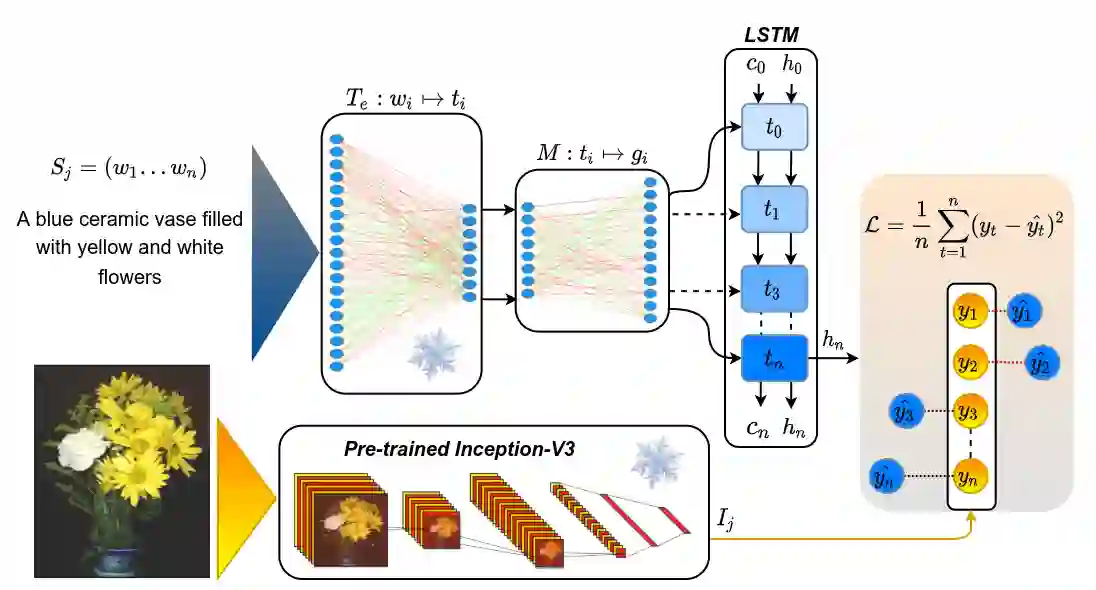
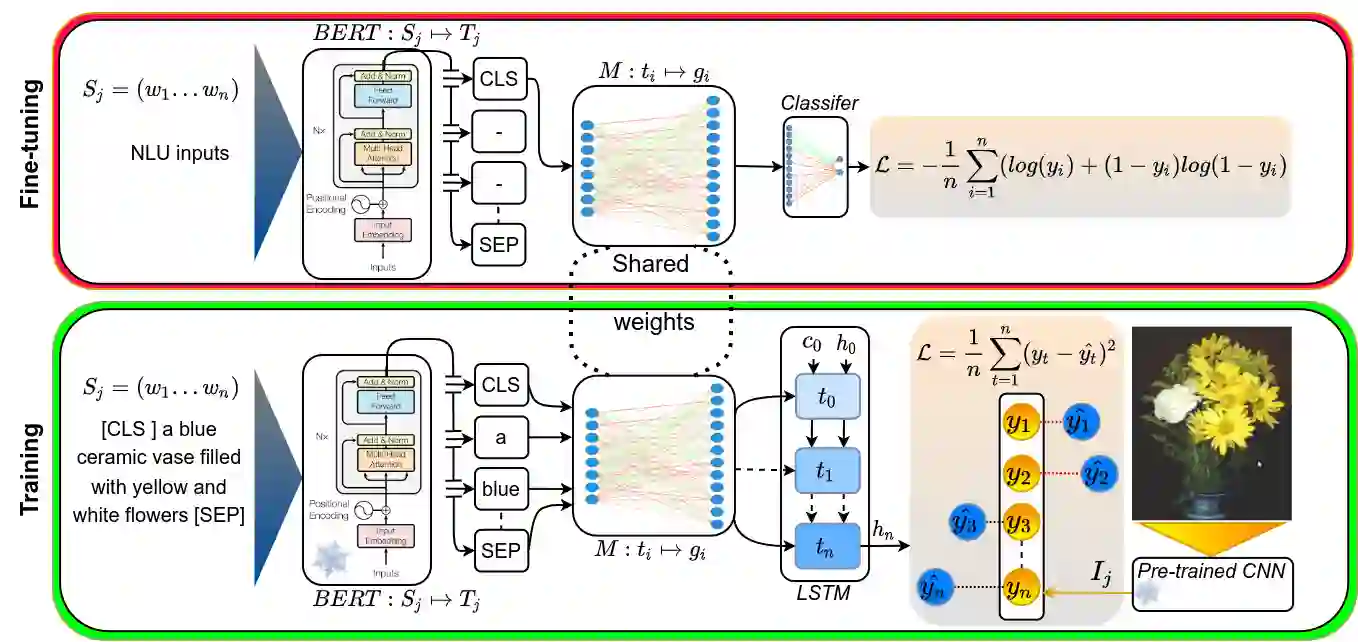
Language grounding to vision is an active field of research aiming to enrich text-based representations of word meanings by leveraging perceptual knowledge from vision. Despite many attempts at language grounding, it is still unclear how to effectively inject visual knowledge into the word embeddings of a language in such a way that a proper balance of textual and visual knowledge is maintained. Some common concerns are the following. Is visual grounding beneficial for abstract words or is its contribution only limited to concrete words? What is the optimal way of bridging the gap between text and vision? How much do we gain by visually grounding textual embeddings? The present study addresses these questions by proposing a simple yet very effective grounding approach for pre-trained word embeddings. Our model aligns textual embeddings with vision while largely preserving the distributional statistics that characterize word use in text corpora. By applying a learned alignment, we are able to generate visually grounded embeddings for unseen words, including abstract words. A series of evaluations on word similarity benchmarks shows that visual grounding is beneficial not only for concrete words, but also for abstract words. We also show that our method for visual grounding offers advantages for contextualized embeddings, but only when these are trained on corpora of relatively modest size. Code and grounded embeddings for English are available at https://github.com/Hazel1994/Visually_Grounded_Word_Embeddings_2.
翻译:视觉语言为视觉奠定基础是一个积极的研究领域,目的是通过利用视觉认知知识来丰富基于文字的文字表达方式; 尽管在语言定位方面做了许多尝试, 但仍不清楚如何有效地将视觉知识注入语言嵌入的语言中, 从而保持文字知识和视觉知识的适当平衡。 下面是一些共同的关切。 视觉基础有利于抽象文字还是其贡献仅限于具体文字? 缩小文字和视觉之间差距的最佳途径是什么? 视觉地面文本嵌入方式能给我们带来多少好处? 1994年的视觉定位不仅有利于具体文字,而且有利于抽象文字。 我们的模型将文字嵌入到语言嵌入的语言中,同时基本上保持文本和视觉知识的适当平衡。 通过应用学习的校正,我们能够产生视觉嵌入的隐蔽内容,包括抽象文字。 一系列关于词汇相似性基准的评估显示,视觉定位基础不仅有利于具体词汇,而且有利于抽象的词汇。 我们还表明,我们经过培训的图像定位G/GO的定位方法在相对的视野地面定位上具有一定的优势。