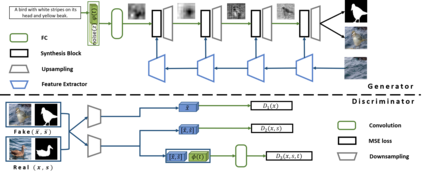
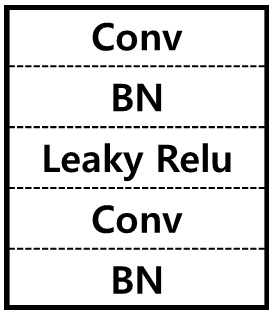
In this paper, we introduce a new method for generating an object image from text attributes on a desired location, when the base image is given. One step further to the existing studies on text-to-image generation mainly focusing on the object's appearance, the proposed method aims to generate an object image preserving the given background information, which is the first attempt in this field. To tackle the problem, we propose a multi-conditional GAN (MC-GAN) which controls both the object and background information jointly. As a core component of MC-GAN, we propose a synthesis block which disentangles the object and background information in the training stage. This block enables MC-GAN to generate a realistic object image with the desired background by controlling the amount of the background information from the given base image using the foreground information from the text attributes. From the experiments with Caltech-200 bird and Oxford-102 flower datasets, we show that our model is able to generate photo-realistic images with a resolution of 128 x 128. The source code of MC-GAN is released.
翻译:在本文中, 当给定基本图像时, 我们采用一种新的方法, 在一个理想位置的文本属性中生成对象图像。 在现有的文本到图像生成研究中, 以对象外观为主的一步是, 拟议的方法旨在生成一个保存给定背景资料的物体图像, 这是这个领域的第一次尝试 。 为了解决这个问题, 我们提议了一个多条件的 GAN (MC- GAN), 共同控制对象和背景信息 。 作为 MC- GAN 的核心组成部分, 我们提议了一个合成块, 将对象和背景信息分解在培训阶段。 这个块使 MC- GAN 能够使用文本属性的地面信息控制从给定底图像中获取的背景资料数量, 从而生成符合预期背景的现实对象图像 。 我们通过与 Caltech- 200 鸟和 Oxford- 102 花数据集的实验, 显示我们的模型能够生成光真化图像, 分辨率为 128 x 128. 。 MC- GAN 源码被发布 。