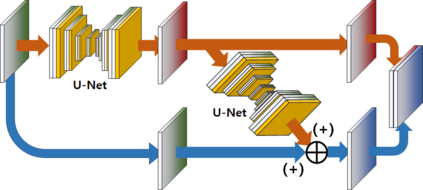
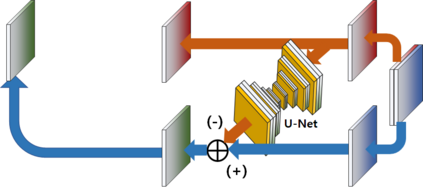
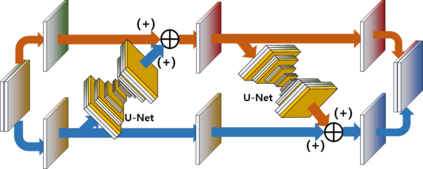
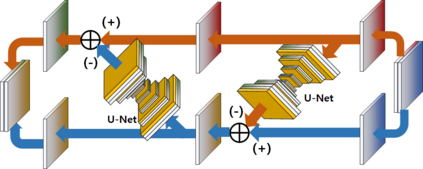
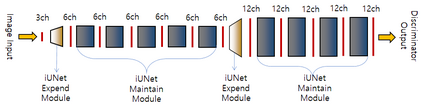
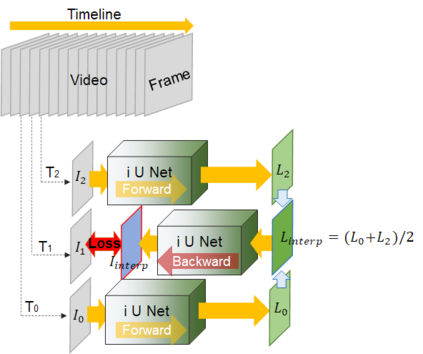
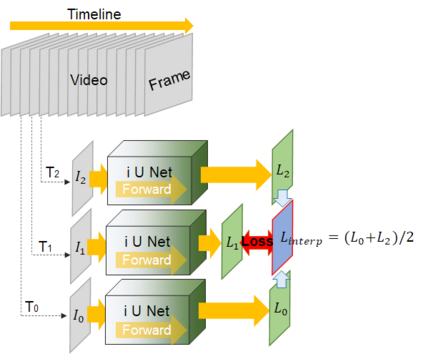
Video frame interpolation is the task of creating an interframe between two adjacent frames along the time axis. So, instead of simply averaging two adjacent frames to create an intermediate image, this operation should maintain semantic continuity with the adjacent frames. Most conventional methods use optical flow, and various tools such as occlusion handling and object smoothing are indispensable. Since the use of these various tools leads to complex problems, we tried to tackle the video interframe generation problem without using problematic optical flow . To enable this , we have tried to use a deep neural network with an invertible structure, and developed an U-Net based Generative Flow which is a modified normalizing flow. In addition, we propose a learning method with a new consistency loss in the latent space to maintain semantic temporal consistency between frames. The resolution of the generated image is guaranteed to be identical to that of the original images by using an invertible network. Furthermore, as it is not a random image like the ones by generative models, our network guarantees stable outputs without flicker. Through experiments, we \sam {confirmed the feasibility of the proposed algorithm and would like to suggest the U-Net based Generative Flow as a new possibility for baseline in video frame interpolation. This paper is meaningful in that it is the world's first attempt to use invertible networks instead of optical flows for video interpolation.
翻译:视频框架的内插是沿时间轴在两个相邻框架之间创建一个间框的任务。 因此, 与其简单地平均两个相邻框架以创建中间图像, 不如将两个相邻框架相邻框架相邻, 操作应该保持与相邻框架的语义连续性。 多数常规方法使用光学流, 以及隐蔽处理和物体平滑等各种工具是不可或缺的。 由于使用这些各种工具会导致复杂的问题, 我们试图在不使用有问题的光学流的情况下解决视频间生成问题。 为了做到这一点, 我们试图使用一个带有不可逆结构的深层神经网络, 并开发了一个基于 U-Net 的导出流, 这是一种经过修改的正常流。 此外, 我们提议了一种学习方法, 在潜在的空间里会丧失新的一致性, 以保持隐蔽的时间一致性。 由于使用这些工具, 我们试图使用这些工具来解决视频的生成问题, 而不是使用有问题的光滑动模式, 我们的网络保证了稳定的输出。 通过实验, 我们确认了基于 U- sam { construal 的 U- prial commal robilation robilation orview view view vical viol viol view view viol view view view viol view view viol view viol viol viol violviolview viol viol viol viol viol viol viol viol viol vical viol viol viol viol vical vical vical viol vical viol vicol 。 。 。 。 。 。 。 。 和 一种以 。 。 一种以 。 一种以 一种以 一种以 一种以 一种以 一种以 一种以 一种以 一种以 一种以 一种以 一种以 一种以 一种以 格式使用新的 一种 格式使用新的 格式使用新的 的纸 。 。