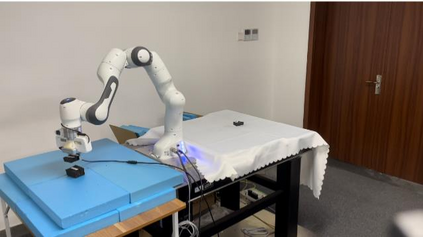
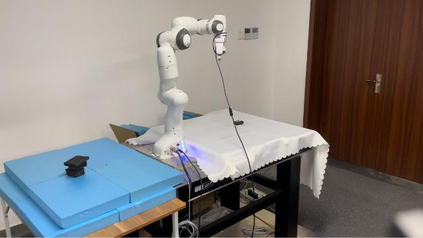
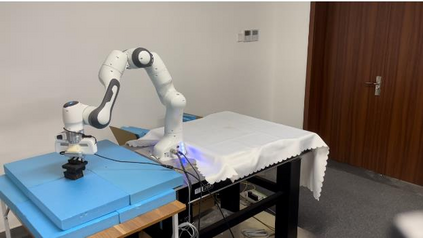
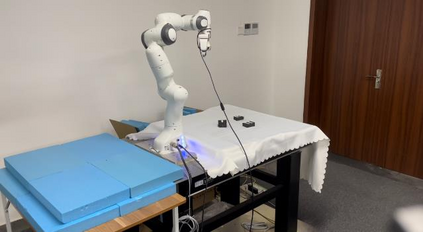
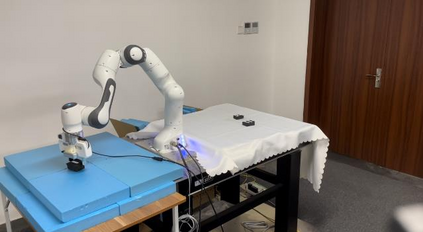
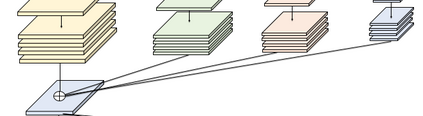
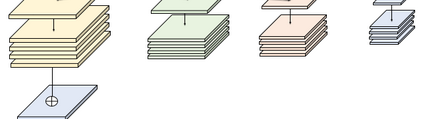
High-resolution representations are important for vision-based robotic grasping problems. Existing works generally encode the input images into low-resolution representations via sub-networks and then recover high-resolution representations. This will lose spatial information, and errors introduced by the decoder will be more serious when multiple types of objects are considered or objects are far away from the camera. To address these issues, we revisit the design paradigm of CNN for robotic perception tasks. We demonstrate that using parallel branches as opposed to serial stacked convolutional layers will be a more powerful design for robotic visual grasping tasks. In particular, guidelines of neural network design are provided for robotic perception tasks, e.g., high-resolution representation and lightweight design, which respond to the challenges in different manipulation scenarios. We then develop a novel grasping visual architecture referred to as HRG-Net, a parallel-branch structure that always maintains a high-resolution representation and repeatedly exchanges information across resolutions. Extensive experiments validate that these two designs can effectively enhance the accuracy of visual-based grasping and accelerate network training. We show a series of comparative experiments in real physical environments at Youtube: https://youtu.be/Jhlsp-xzHFY.
翻译:高分辨率表示方式对于基于视觉的机器人捕捉问题十分重要。 现有的作品一般通过子网络将输入图像编码成低分辨率表示方式,然后恢复高分辨率表示方式。 这将失去空间信息,当考虑多种类型的物体或远离相机的物体时,解码器引入的错误将更为严重。 为了解决这些问题,我们重新审视CNN对机器人感知任务的设计范式。 我们证明,使用平行分支而不是串列堆叠的连叠共振动层,将是机器人视觉捕捉任务的更强有力的设计。 特别是,为机器人感知任务提供了神经网络设计准则,例如高分辨率表示方式和轻度设计,以应对不同操作情景中的挑战。 然后,我们开发了被称为HRG-Net的新颖的抓取视觉结构,这是一个平行的分支结构,它总是保持高分辨率表示方式,并反复在各决议中交流信息。 我们广泛的实验证实,这两种设计能够有效地提高视觉捕捉和加速网络培训的准确性。 我们展示了在Youtube真实物理环境中的一系列比较实验: https://youxyxYbe/hlsp。