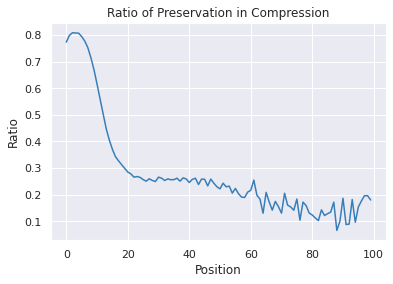
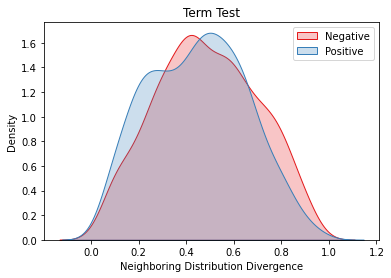
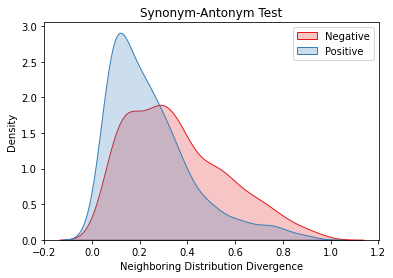
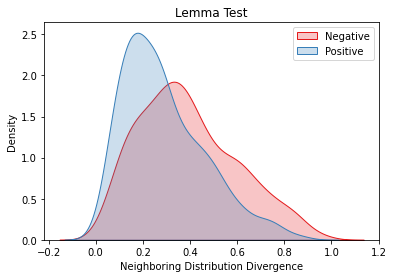
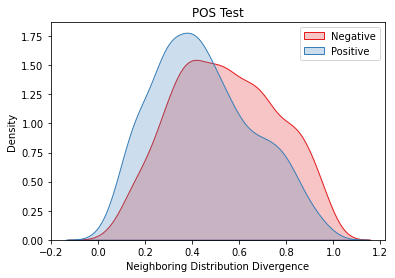
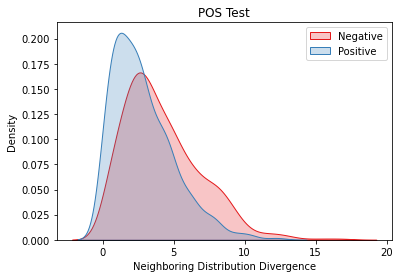
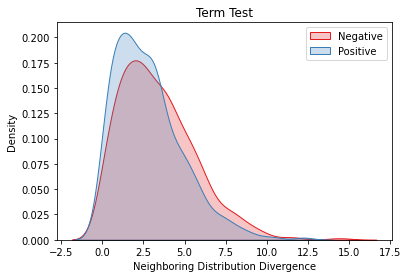
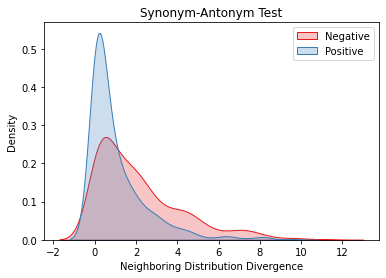
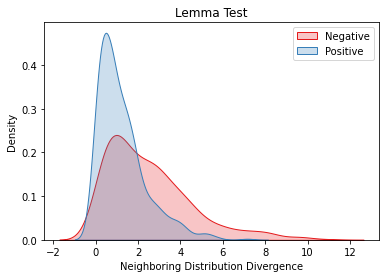
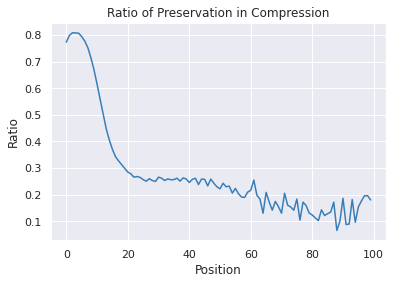
Overlapping frequently occurs in paired texts in natural language processing tasks like text editing and semantic similarity evaluation. Better evaluation of the semantic distance between the overlapped sentences benefits the language system's understanding and guides the generation. Since conventional semantic metrics are based on word representations, they are vulnerable to the disturbance of overlapped components with similar representations. This paper aims to address the issue with a mask-and-predict strategy. We take the words in the longest common sequence (LCS) as neighboring words and use masked language modeling (MLM) from pre-trained language models (PLMs) to predict the distributions on their positions. Our metric, Neighboring Distribution Divergence (NDD), represent the semantic distance by calculating the divergence between distributions in the overlapped parts. Experiments on Semantic Textual Similarity show NDD to be more sensitive to various semantic differences, especially on highly overlapped paired texts. Based on the discovery, we further implement an unsupervised and training-free method for text compression, leading to a significant improvement on the previous perplexity-based method. The high scalability of our method even enables NDD to outperform the supervised state-of-the-art in domain adaption by a huge margin. Further experiments on syntax and semantics analyses verify the awareness of internal sentence structures, indicating the high potential of NDD for further studies.
翻译:暂无翻译