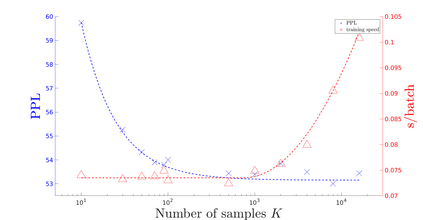
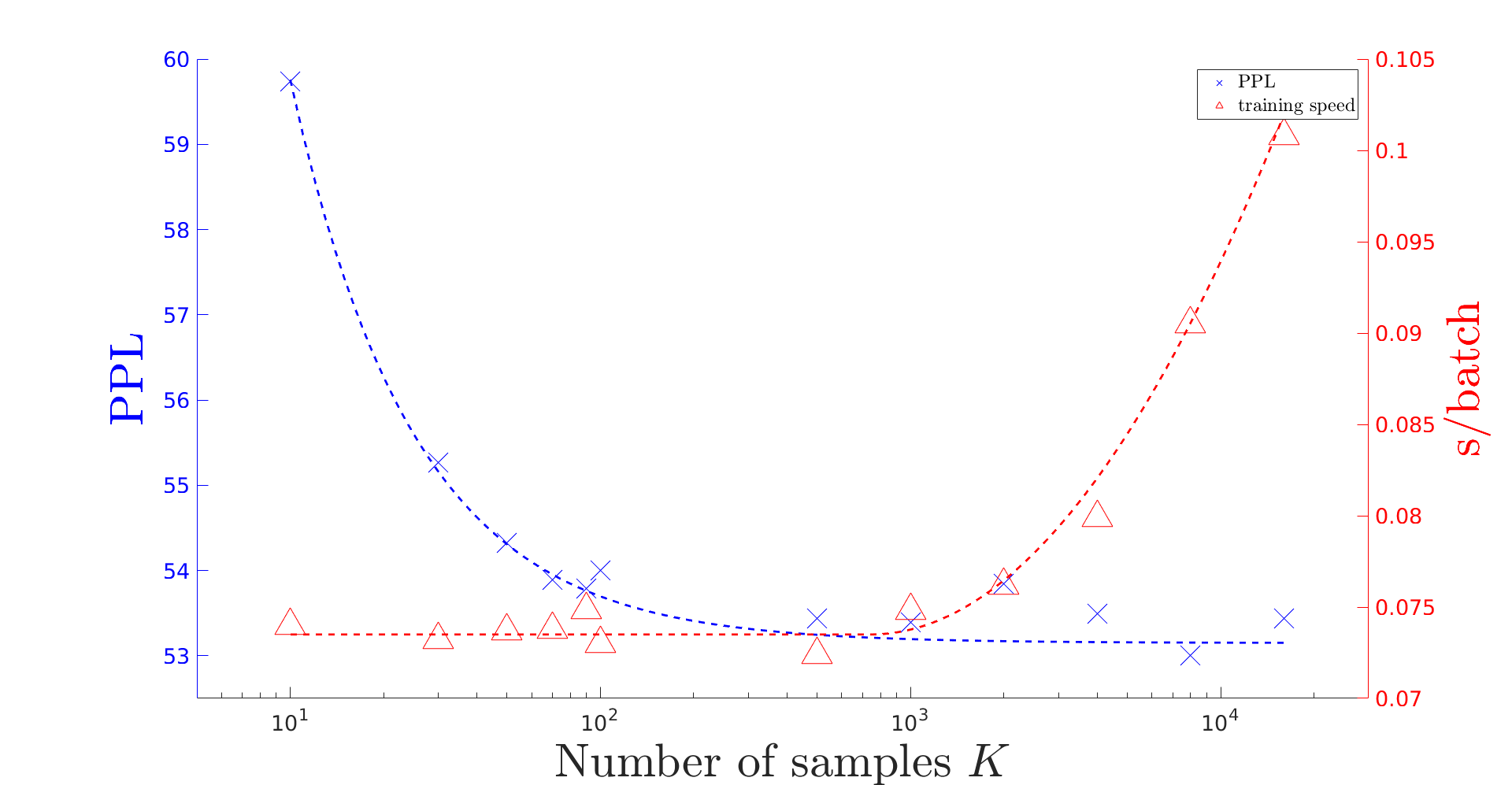
To mitigate the problem of having to traverse over the full vocabulary in the softmax normalization of a neural language model, sampling-based training criteria are proposed and investigated in the context of large vocabulary word-based neural language models. These training criteria typically enjoy the benefit of faster training and testing, at a cost of slightly degraded performance in terms of perplexity and almost no visible drop in word error rate. While noise contrastive estimation is one of the most popular choices, recently we show that other sampling-based criteria can also perform well, as long as an extra correction step is done, where the intended class posterior probability is recovered from the raw model outputs. In this work, we propose self-normalized importance sampling. Compared to our previous work, the criteria considered in this work are self-normalized and there is no need to further conduct a correction step. Compared to noise contrastive estimation, our method is directly comparable in terms of complexity in application. Through self-normalized language model training as well as lattice rescoring experiments, we show that our proposed self-normalized importance sampling is competitive in both research-oriented and production-oriented automatic speech recognition tasks.
翻译:为了减轻在神经语言模式的软体正常化中绕过全部词汇的问题,在大型词汇单词神经语言模式的背景下,提出和调查基于抽样的培训标准。这些培训标准通常具有更快的培训和测试的好处,其代价是,在迷惑性方面表现略微下降,字词错误率几乎没有明显下降。虽然噪声对比估计是最受欢迎的选择之一,但最近我们表明,其他基于抽样的标准也可以很好地发挥作用,只要采取额外的纠正步骤,从原始模型产出中恢复预期的阶级后继概率。我们在此工作中提出自我标准化的重要性抽样。与我们以前的工作相比,这项工作中考虑的标准是自我正常化的,没有必要进一步采取纠正步骤。与噪音对比估计相比,我们的方法在应用的复杂性方面是直接可比的。通过自我标准化语言模式培训以及Lattice重新校准实验,我们提出的自我标准化重要性抽样在面向研究的任务和面向生产的自动语音识别任务中都具有竞争力。