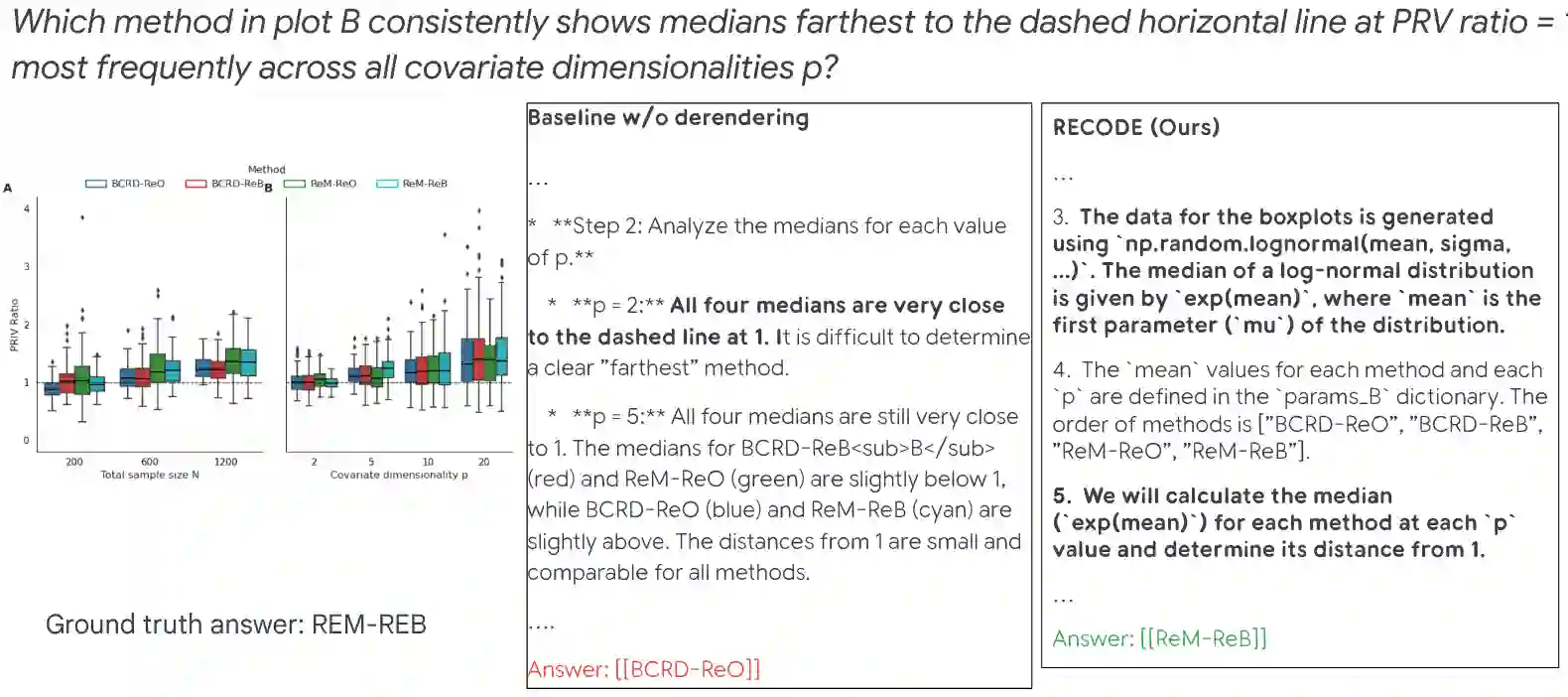
Multimodal Large Language Models (MLLMs) struggle with precise reasoning for structured visuals like charts and diagrams, as pixel-based perception lacks a mechanism for verification. To address this, we propose to leverage derendering -- the process of reverse-engineering visuals into executable code -- as a new modality for verifiable visual reasoning. Specifically, we propose RECODE, an agentic framework that first generates multiple candidate programs to reproduce the input image. It then uses a critic to select the most faithful reconstruction and iteratively refines the code. This process not only transforms an ambiguous perceptual task into a verifiable, symbolic problem, but also enables precise calculations and logical inferences later on. On various visual reasoning benchmarks such as CharXiv, ChartQA, and Geometry3K, RECODE significantly outperforms methods that do not leverage code or only use code for drawing auxiliary lines or cropping. Our work demonstrates that grounding visual perception in executable code provides a new path toward more accurate and verifiable multimodal reasoning.
翻译:多模态大语言模型(MLLMs)在处理图表和示意图等结构化视觉内容的精确推理方面存在困难,因为基于像素的感知缺乏验证机制。为解决此问题,我们提出利用反渲染——将视觉内容逆向工程为可执行代码的过程——作为一种新的模态,以实现可验证的视觉推理。具体而言,我们提出了RECODE,这是一个代理框架,首先生成多个候选程序来复现输入图像。随后,它使用一个评判器选择最忠实于原图的重建结果,并迭代优化代码。这一过程不仅将模糊的感知任务转化为可验证的符号问题,还使得后续能够进行精确计算和逻辑推理。在CharXiv、ChartQA和Geometry3K等多种视觉推理基准测试中,RECODE显著优于那些不利用代码或仅将代码用于绘制辅助线或裁剪的方法。我们的工作表明,将视觉感知建立在可执行代码之上,为更准确、可验证的多模态推理提供了一条新路径。