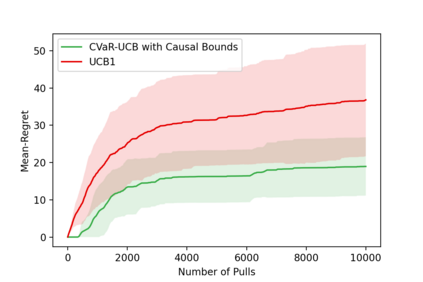
In this paper, we consider a risk-averse multi-armed bandit (MAB) problem where the goal is to learn a policy that minimizes the risk of low expected return, as opposed to maximizing the expected return itself, which is the objective in the usual approach to risk-neutral MAB. Specifically, we formulate this problem as a transfer learning problem between an expert and a learner agent in the presence of contexts that are only observable by the expert but not by the learner. Thus, such contexts are unobserved confounders (UCs) from the learner's perspective. Given a dataset generated by the expert that excludes the UCs, the goal for the learner is to identify the true minimum-risk arm with fewer online learning steps, while avoiding possible biased decisions due to the presence of UCs in the expert's data.
翻译:在本文中,我们考虑了一个反风险的多武装土匪问题,其目标是学习一种政策,尽量减少预期回报率低的风险,而不是尽量扩大预期回报率本身,这是对风险中性土匪的通常做法中的目标。具体地说,我们将这一问题描述为专家与学习者代理人之间在只有专家能观察,而不是学习者无法观察的情况下的转移学习问题。因此,从学习者的观点来看,这种背景是无法观察到的困惑者。鉴于专家生成的数据集不包括UCs,学习者的目标是确定真正的最低风险部分,减少在线学习步骤,同时避免由于UCs在专家数据中的存在而可能作出有偏见的决定。