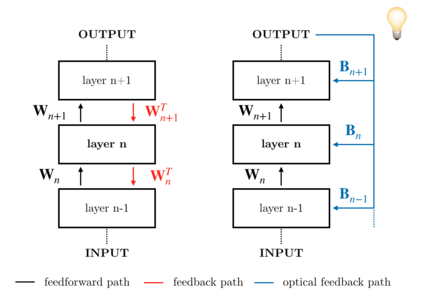
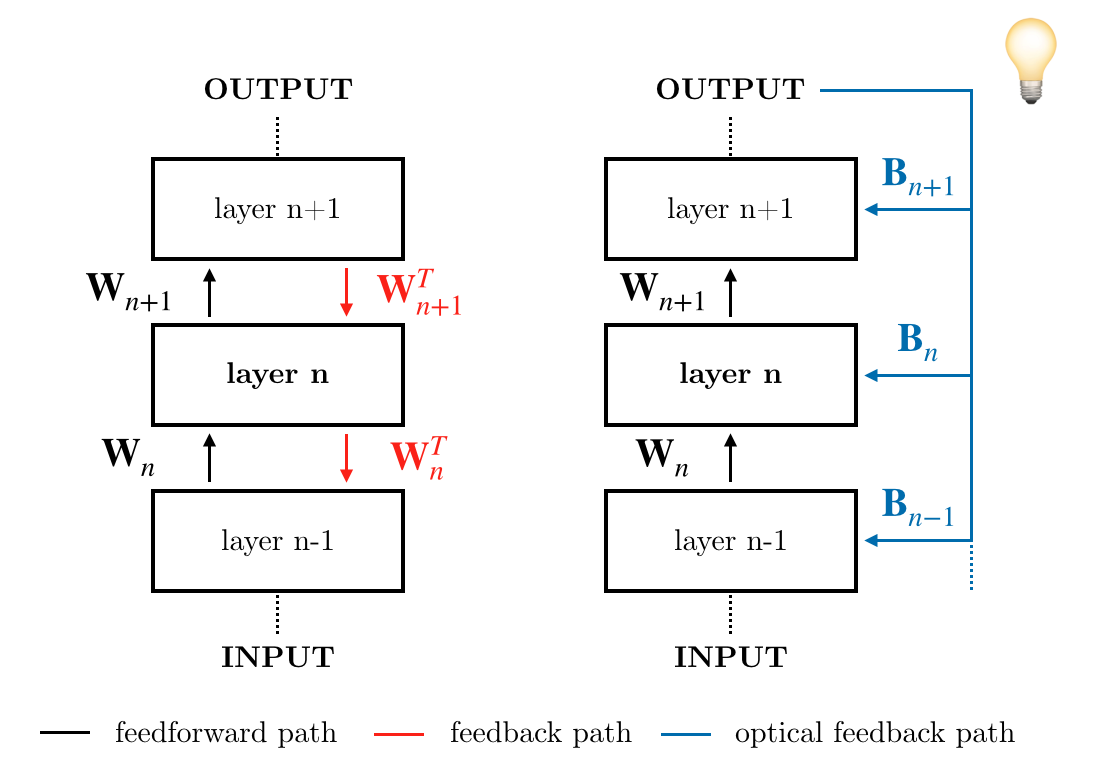
The scaling hypothesis motivates the expansion of models past trillions of parameters as a path towards better performance. Recent significant developments, such as GPT-3, have been driven by this conjecture. However, as models scale-up, training them efficiently with backpropagation becomes difficult. Because model, pipeline, and data parallelism distribute parameters and gradients over compute nodes, communication is challenging to orchestrate: this is a bottleneck to further scaling. In this work, we argue that alternative training methods can mitigate these issues, and can inform the design of extreme-scale training hardware. Indeed, using a synaptically asymmetric method with a parallelizable backward pass, such as Direct Feedback Alignement, communication needs are drastically reduced. We present a photonic accelerator for Direct Feedback Alignment, able to compute random projections with trillions of parameters. We demonstrate our system on benchmark tasks, using both fully-connected and graph convolutional networks. Our hardware is the first architecture-agnostic photonic co-processor for training neural networks. This is a significant step towards building scalable hardware, able to go beyond backpropagation, and opening new avenues for deep learning.
翻译:缩放假设刺激了过去数万亿参数模型的扩展,作为改善绩效的途径。最近的重大发展,如GPT-3-3号模型,是由这一推测驱动的。然而,随着模型的扩大,以反向反向反向法对其进行有效培训变得十分困难。由于模型、管道和数据平行法分布参数和梯度,计算节点的计算,通信具有挑战性:这是进一步缩小规模的瓶颈。在这项工作中,我们认为,替代培训方法可以缓解这些问题,也可以为极端规模培训硬件的设计提供参考。事实上,使用同步的不对称方法,同时使用可平行反向的反向通道,例如直接反向感应,通信需求就会急剧减少。我们展示了直接反向协调光学加速器,能够用数万亿参数进行随机预测。我们在基准任务上展示了我们的系统,同时使用完全连接的和图图式的革命网络。我们的硬件是用于培训神经网络的第一个建筑-不可知光共处理器。这是朝向建造可缩的硬件迈出的重要一步,能够超越反向反向反向反向反向方向,打开新的学习新途径。