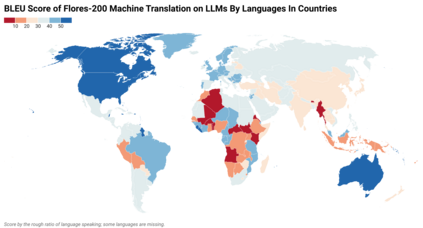
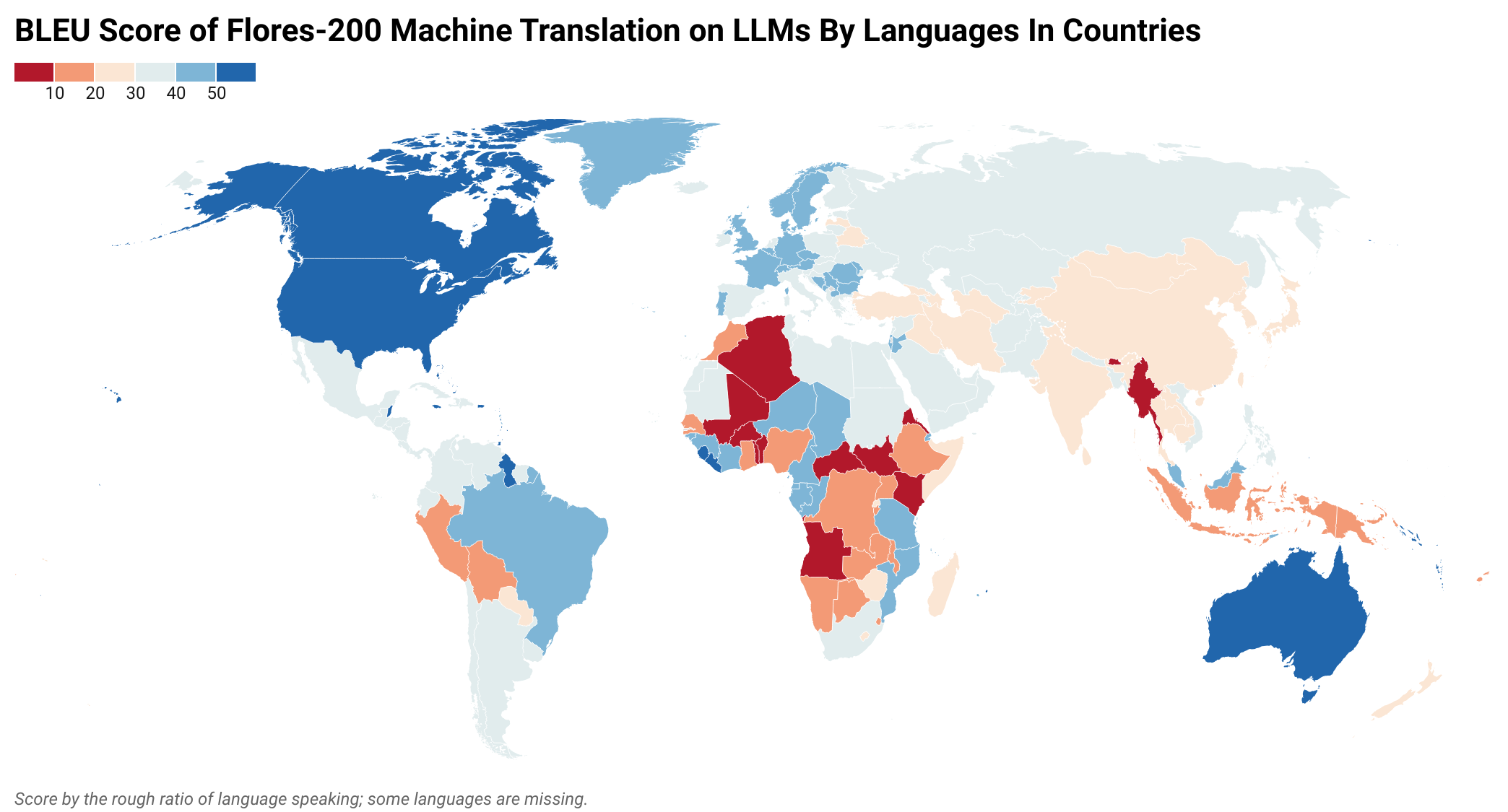
Low-Resource Languages (LRLs) present significant challenges in natural language processing due to their limited linguistic resources and underrepresentation in standard datasets. While recent advancements in Large Language Models (LLMs) and Neural Machine Translation (NMT) have substantially improved translation capabilities for high-resource languages, performance disparities persist for LRLs, particularly impacting privacy-sensitive and resource-constrained scenarios. This paper systematically evaluates the limitations of current LLMs across 200 languages using benchmarks such as FLORES-200. We also explore alternative data sources, including news articles and bilingual dictionaries, and demonstrate how knowledge distillation from large pre-trained models can significantly improve smaller LRL translations. Additionally, we investigate various fine-tuning strategies, revealing that incremental enhancements markedly reduce performance gaps on smaller LLMs.
翻译:暂无翻译