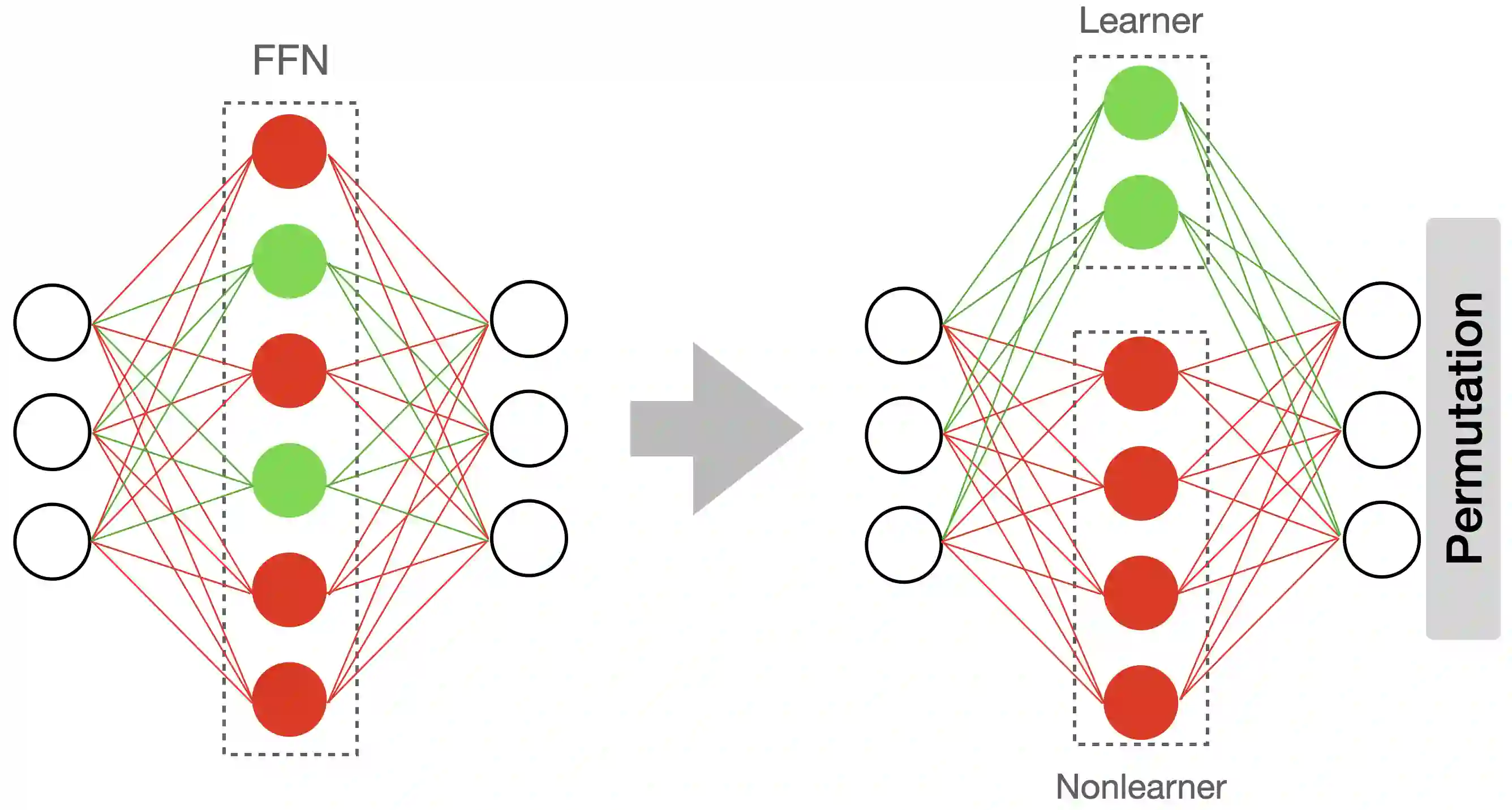
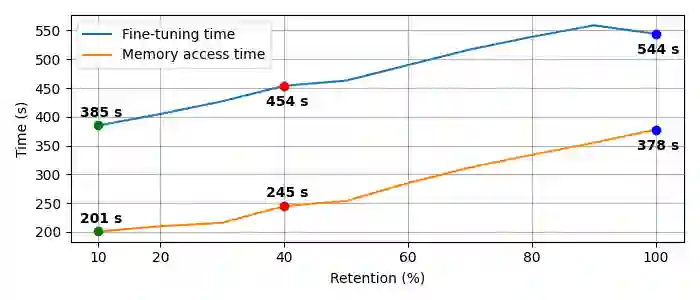
Resource-constrained devices are increasingly the deployment targets of machine learning applications. Static models, however, do not always suffice for dynamic environments. On-device training of models allows for quick adaptability to new scenarios. With the increasing size of deep neural networks, as noted with the likes of BERT and other natural language processing models, comes increased resource requirements, namely memory, computation, energy, and time. Furthermore, training is far more resource intensive than inference. Resource-constrained on-device learning is thus doubly difficult, especially with large BERT-like models. By reducing the memory usage of fine-tuning, pre-trained BERT models can become efficient enough to fine-tune on resource-constrained devices. We propose Freeze And Reconfigure (FAR), a memory-efficient training regime for BERT-like models that reduces the memory usage of activation maps during fine-tuning by avoiding unnecessary parameter updates. FAR reduces fine-tuning time on the DistilBERT model and CoLA dataset by 30%, and time spent on memory operations by 47%. More broadly, reductions in metric performance on the GLUE and SQuAD datasets are around 1% on average.
翻译:受资源限制的装置日益成为机器学习应用的部署目标。但是,静态模型并非总能满足动态环境的需要。模型的在线设备培训能够迅速适应新的情景。随着深度神经网络规模的扩大,如BERT和其他自然语言处理模型等,资源需求也随之增加,即记忆、计算、能量和时间。此外,培训比推断要密集得多得多。因此,受资源限制的脱机学习是加倍困难的,特别是大型BERT型模型。通过减少微调的记忆用量,预先训练的BERT型模型可以变得足够高效,能够对资源限制的装置进行微调。我们提议为类似BERT型模型建立一个记忆高效的培训机制,通过避免不必要的参数更新,减少在微调时对激活地图的记忆使用。FART将DITERT模型和COLA数据集的微调时间减少30%,用于记忆操作的时间则减少47%。更广泛而言,GLUE和SUAD数据设置的计量性工作将减少。