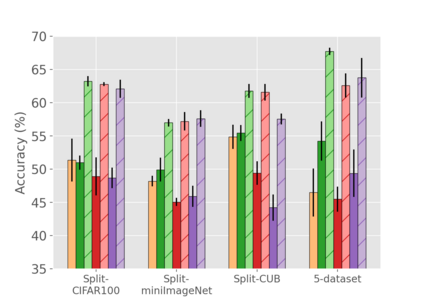
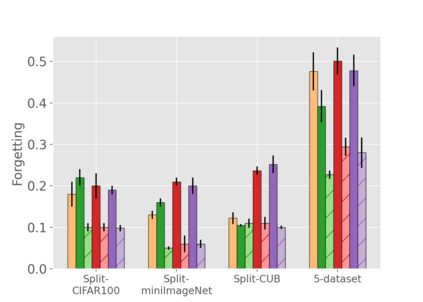
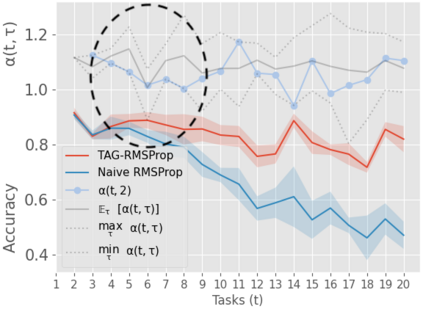
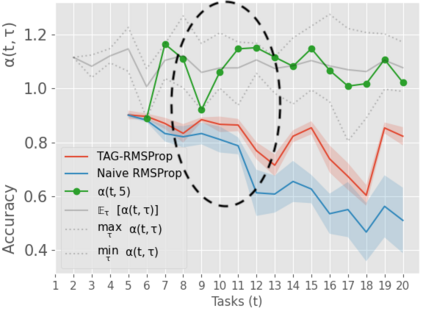
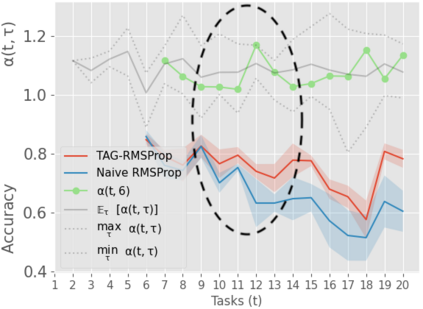
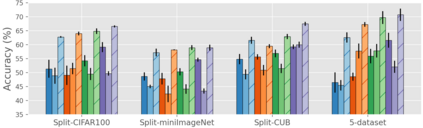
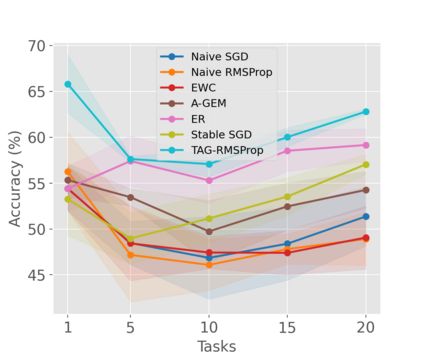
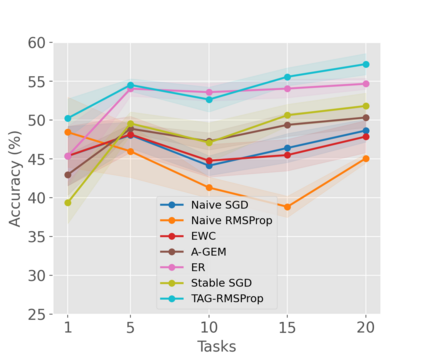
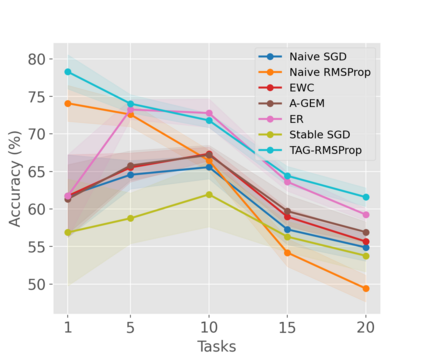
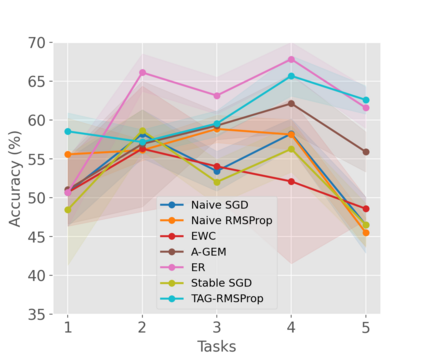
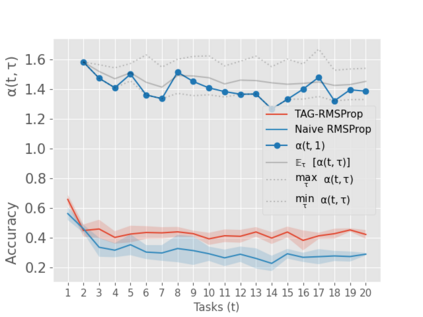
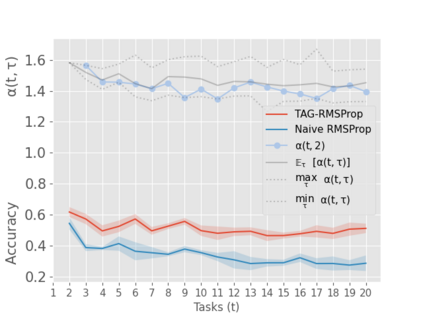
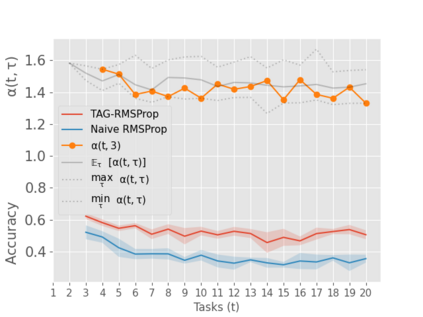
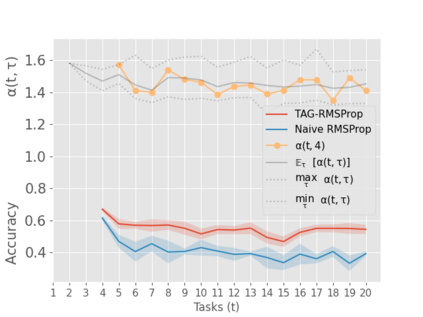
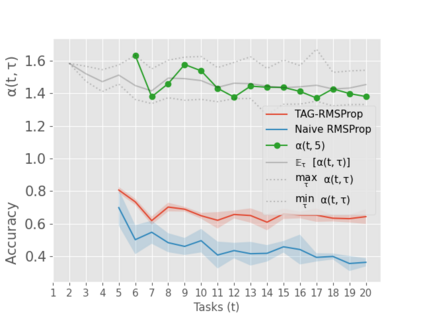
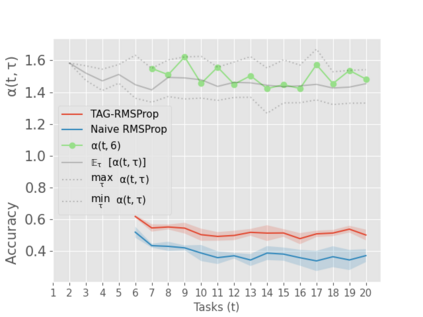
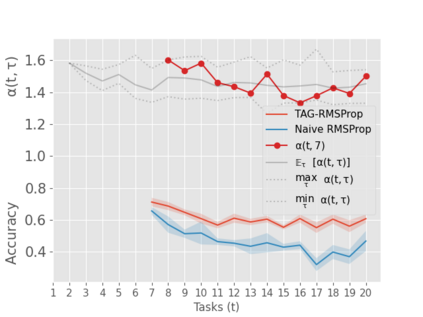
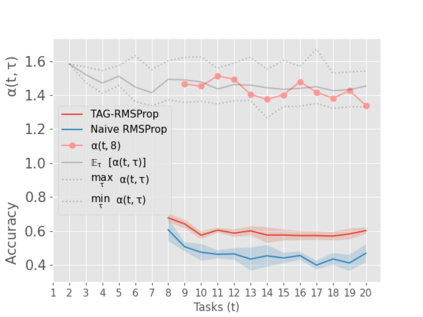
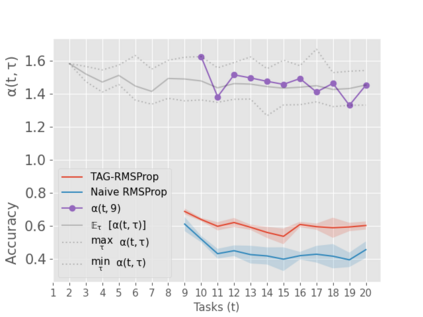
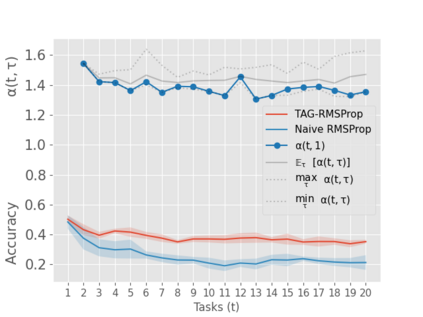
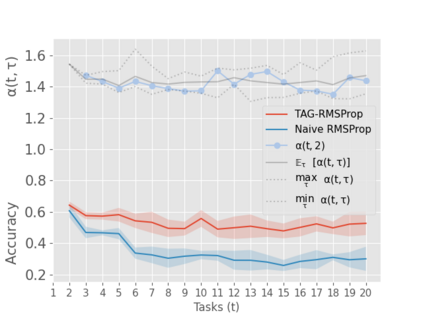
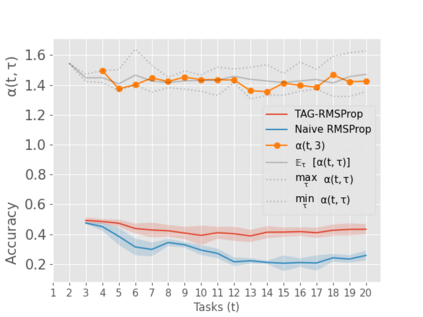
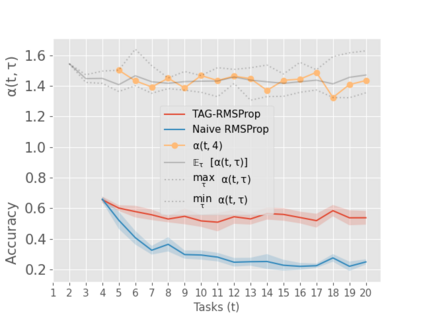
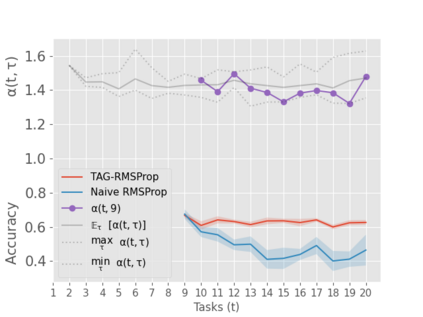
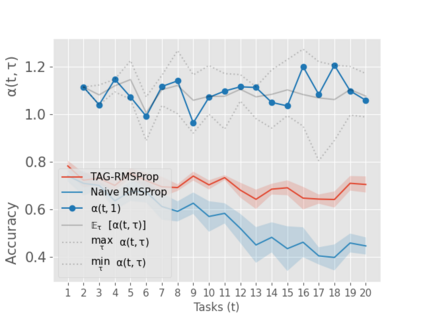
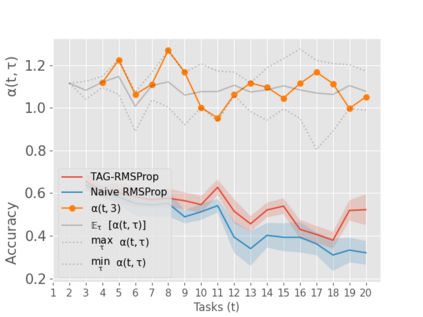
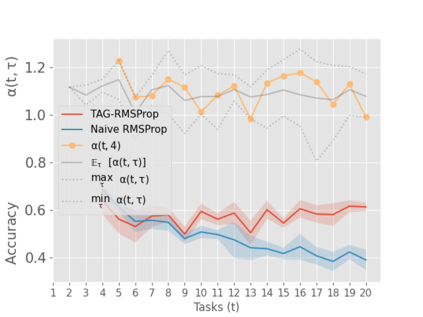
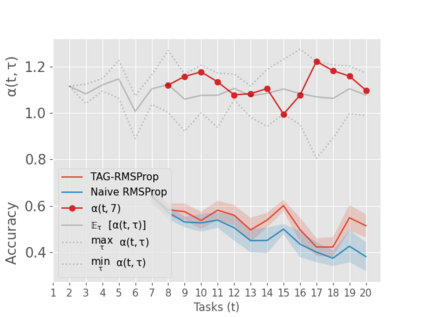
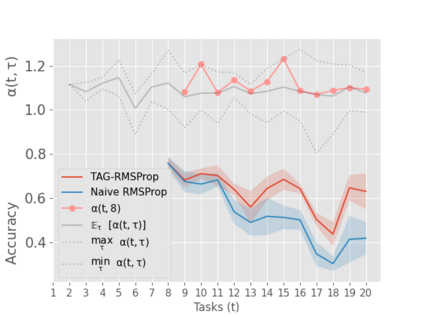
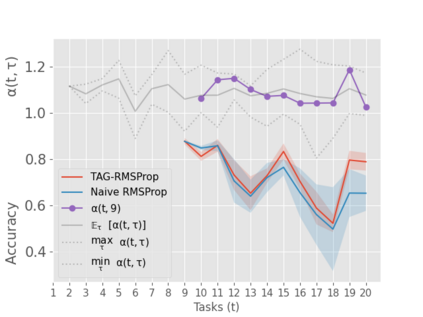
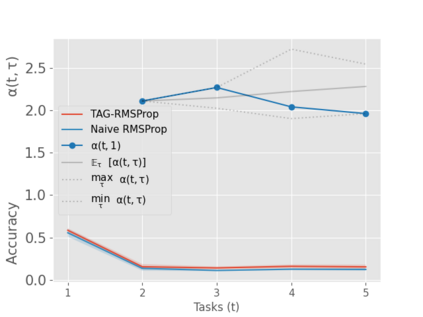
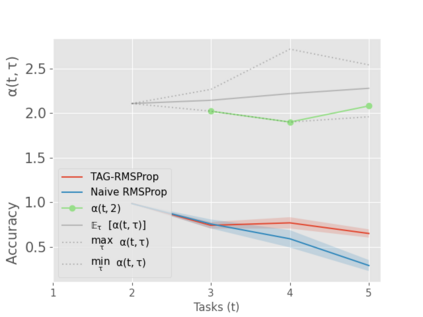
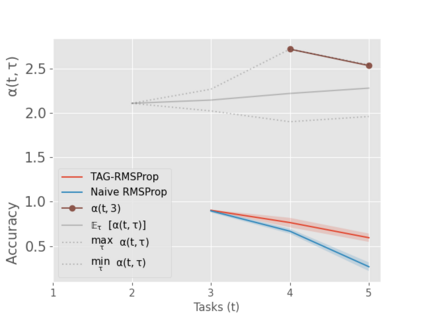
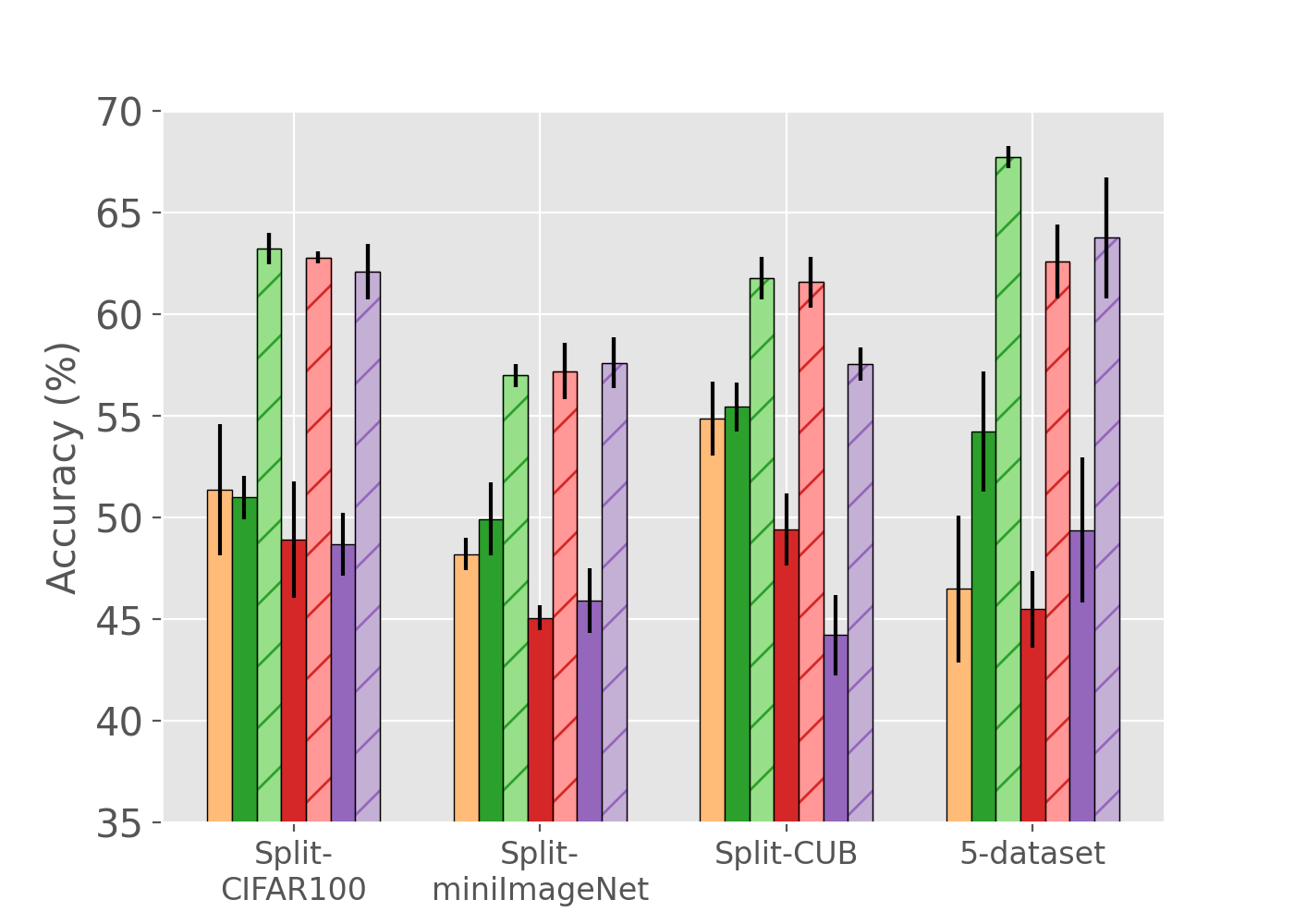
When an agent encounters a continual stream of new tasks in the lifelong learning setting, it leverages the knowledge it gained from the earlier tasks to help learn the new tasks better. In such a scenario, identifying an efficient knowledge representation becomes a challenging problem. Most research works propose to either store a subset of examples from the past tasks in a replay buffer, dedicate a separate set of parameters to each task or penalize excessive updates over parameters by introducing a regularization term. While existing methods employ the general task-agnostic stochastic gradient descent update rule, we propose a task-aware optimizer that adapts the learning rate based on the relatedness among tasks. We utilize the directions taken by the parameters during the updates by accumulating the gradients specific to each task. These task-based accumulated gradients act as a knowledge base that is maintained and updated throughout the stream. We empirically show that our proposed adaptive learning rate not only accounts for catastrophic forgetting but also allows positive backward transfer. We also show that our method performs better than several state-of-the-art methods in lifelong learning on complex datasets with a large number of tasks.
翻译:当一个代理机构在终身学习环境中遇到一连串的新任务时,它会利用其从早期任务中获得的知识来帮助更好地学习新任务。在这样的情况下,确定高效的知识代表方式将成为一个具有挑战性的问题。大多数研究提议要么将过去任务中的一系列实例储存在重放缓冲中,为每项任务单独设定一套参数,或通过引入一个正规化术语来惩罚过多更新参数。虽然现有方法使用一般任务不可知的梯度梯度更新规则,但我们提议了一个任务认知优化器,根据各项任务之间的关联性调整学习率。我们利用在更新过程中根据参数确定的方向,积累每项任务特有的梯度。这些基于任务的累积梯度作为整个流中维持和更新的知识库。我们从经验上表明,我们提议的适应学习率不仅考虑到灾难性的遗忘,而且还允许积极的后向转移。我们还表明,我们的方法比在大量任务的复杂数据集上终身学习的一些最先进的方法要好。