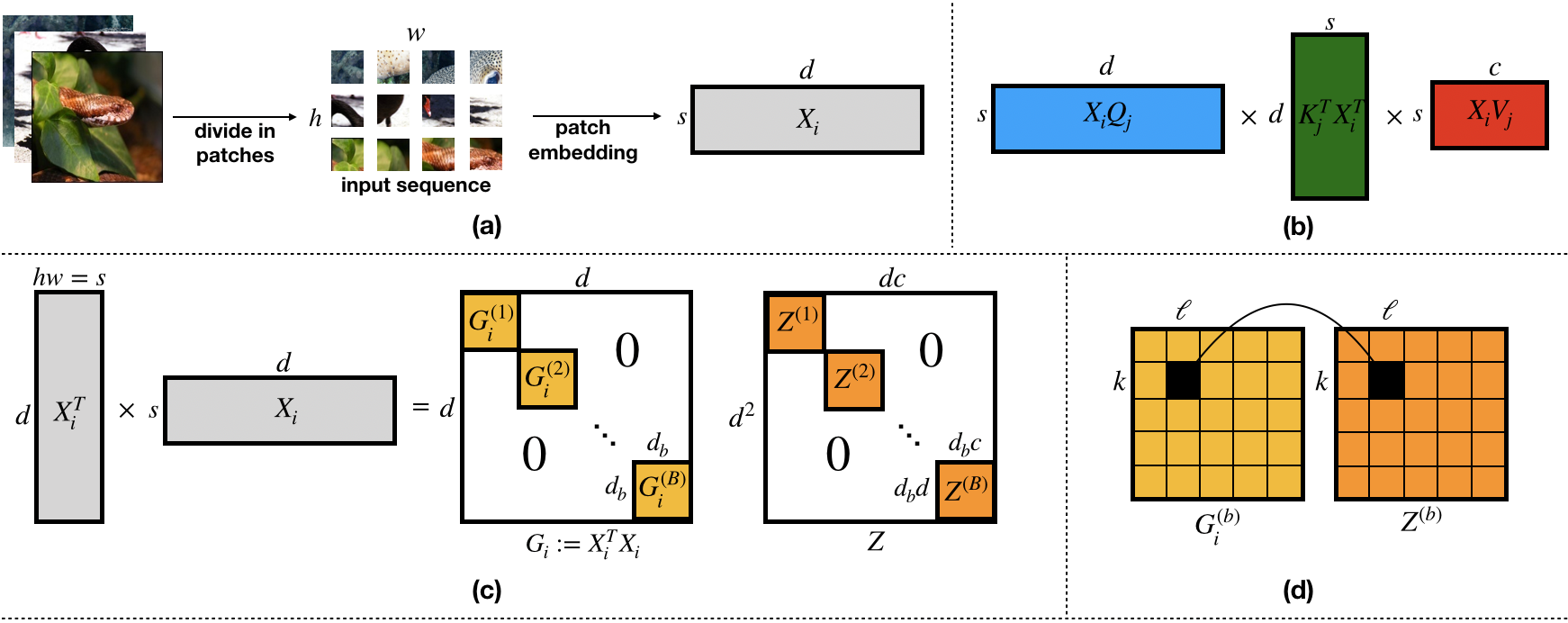
Vision transformers using self-attention or its proposed alternatives have demonstrated promising results in many image related tasks. However, the underpinning inductive bias of attention is not well understood. To address this issue, this paper analyzes attention through the lens of convex duality. For the non-linear dot-product self-attention, and alternative mechanisms such as MLP-mixer and Fourier Neural Operator (FNO), we derive equivalent finite-dimensional convex problems that are interpretable and solvable to global optimality. The convex programs lead to {\it block nuclear-norm regularization} that promotes low rank in the latent feature and token dimensions. In particular, we show how self-attention networks implicitly clusters the tokens, based on their latent similarity. We conduct experiments for transferring a pre-trained transformer backbone for CIFAR-100 classification by fine-tuning a variety of convex attention heads. The results indicate the merits of the bias induced by attention compared with the existing MLP or linear heads.
翻译:使用自我关注或其拟议替代品的视觉变压器在许多与图像有关的任务中显示出了可喜的结果。 但是,人们并没有很好地理解关注的内在偏向。 为了解决这一问题,本文件通过细微的双重性透镜分析了注意力。 对于非线性点产品自我关注以及MLP-混合器和Fourier神经操作器(FNO)等替代机制,我们得出了可解释和可与全球最佳性相容的等同的有限维共解问题。convex 程序导致在潜伏特征和象征层面中提升低等级的 Whit bull entic-norm 正规化 } 。我们特别展示了基于其潜在相似性的自我关注网络隐含的符号组合。我们进行了实验,通过微调调各种CFAR-100级的注意头来为CIFAR-100级转让预先训练的变压器骨。结果表明,与现有的 MLP 或线性头相比,引起注意的偏差是有道理的。