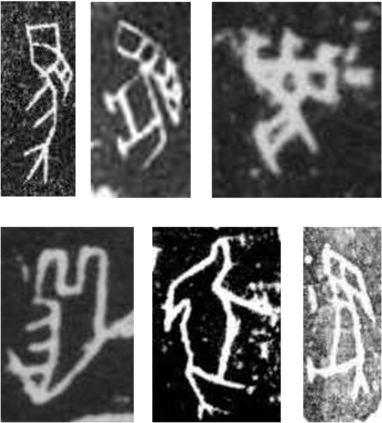
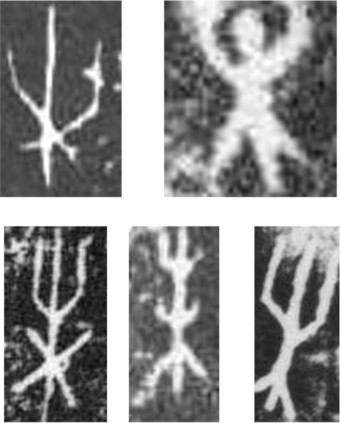
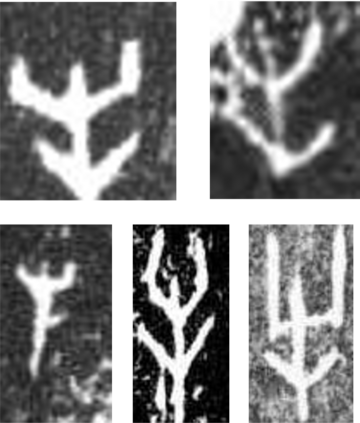
We introduce the Oracle-MNIST dataset, comprising of 28$\times $28 grayscale images of 30,222 ancient characters from 10 categories, for benchmarking pattern classification, with particular challenges on image noise and distortion. The training set totally consists of 27,222 images, and the test set contains 300 images per class. Oracle-MNIST shares the same data format with the original MNIST dataset, allowing for direct compatibility with all existing classifiers and systems, but it constitutes a more challenging classification task than MNIST. The images of ancient characters suffer from 1) extremely serious and unique noises caused by three-thousand years of burial and aging and 2) dramatically variant writing styles by ancient Chinese, which all make them realistic for machine learning research. The dataset is freely available at https://github.com/wm-bupt/oracle-mnist.
翻译:我们引入了甲骨文-MNIST数据集,该数据集由28美元计时的28个灰色图像组成,包括来自10类的30 222个古代字符的28个灰色图像,用于基准模式分类,在图像噪声和扭曲方面特别具有挑战性。培训集完全由27 222个图像组成,测试集每类包含300个图像。甲骨文-MNIST与原有的MNIST数据集有着相同的数据格式,允许与所有现有的分类和系统直接兼容,但与MNIST相比,这是一个更具挑战性的分类任务。古代字符的图像有:1)由三年的埋葬和老化造成的极其严重和独特的噪音,2)由古代中国人造成的急剧变异的写作风格,这些风格都使机器学习研究具有现实性。数据集可以在https://github.com/wm-but/orcle-mnist-mnist免费查阅。