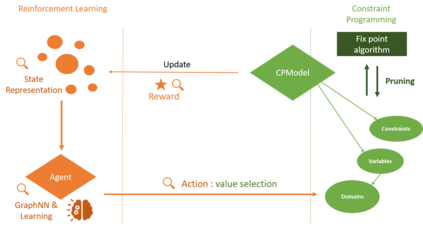
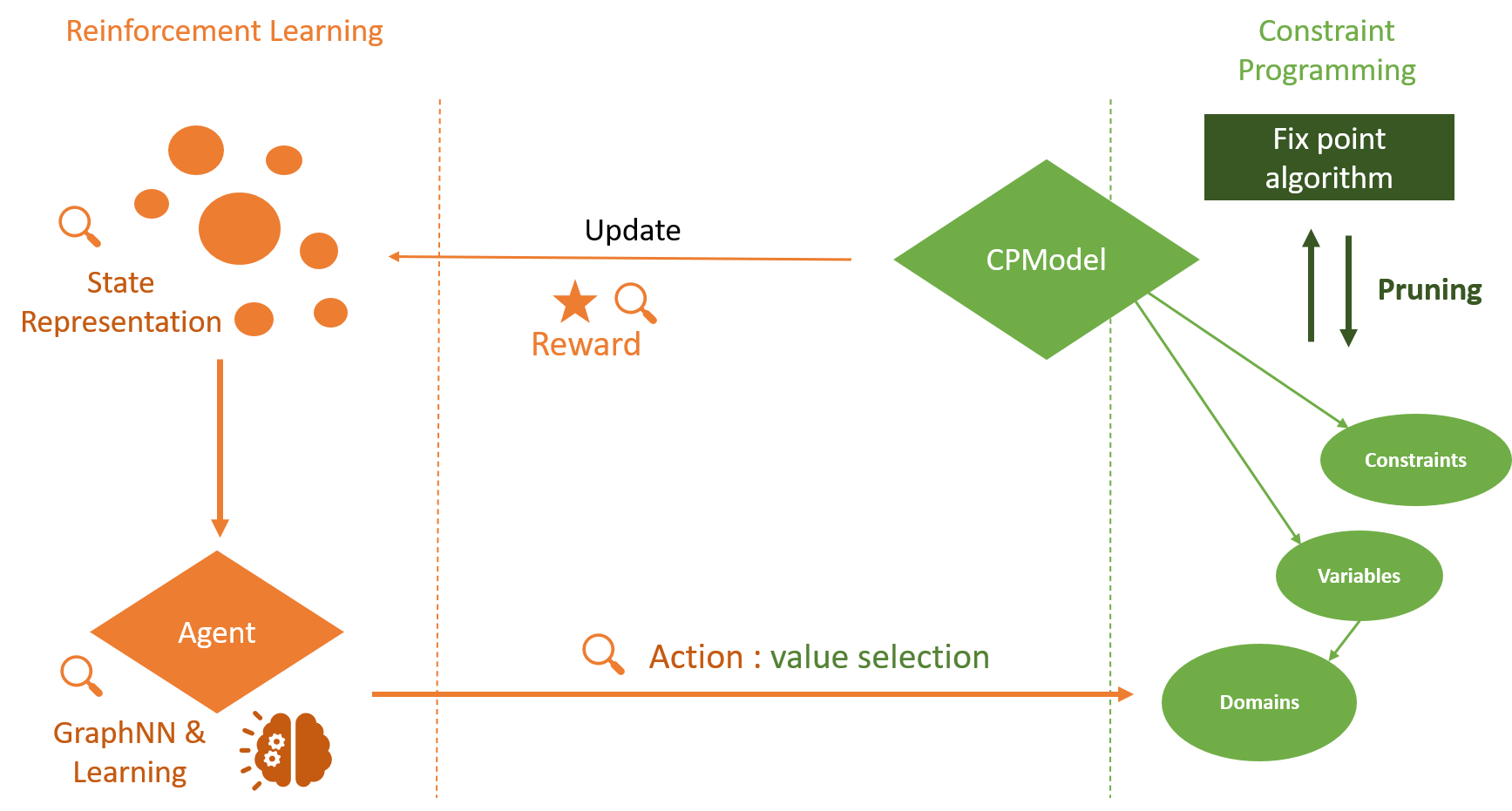
The design of efficient and generic algorithms for solving combinatorial optimization problems has been an active field of research for many years. Standard exact solving approaches are based on a clever and complete enumeration of the solution set. A critical and non-trivial design choice with such methods is the branching strategy, directing how the search is performed. The last decade has shown an increasing interest in the design of machine learning-based heuristics to solve combinatorial optimization problems. The goal is to leverage knowledge from historical data to solve similar new instances of a problem. Used alone, such heuristics are only able to provide approximate solutions efficiently, but cannot prove optimality nor bounds on their solution. Recent works have shown that reinforcement learning can be successfully used for driving the search phase of constraint programming (CP) solvers. However, it has also been shown that this hybridization is challenging to build, as standard CP frameworks do not natively include machine learning mechanisms, leading to some sources of inefficiencies. This paper presents the proof of concept for SeaPearl, a new CP solver implemented in Julia, that supports machine learning routines in order to learn branching decisions using reinforcement learning. Support for modeling the learning component is also provided. We illustrate the modeling and solution performance of this new solver on two problems. Although not yet competitive with industrial solvers, SeaPearl aims to provide a flexible and open-source framework in order to facilitate future research in the hybridization of constraint programming and machine learning.
翻译:多年来,设计解决组合优化问题的高效通用算法一直是一个积极的研究领域。标准精确的解决方法基于对解决方案集的精明和完整列举。一种关键和非三重的设计选择是分流战略,指导搜索如何进行。过去十年已经表明对设计基于机械学习的混合法以解决组合优化问题的兴趣日益增长,目的是利用历史数据的知识解决类似的新问题。光是使用这种超常方法只能提供近似的解决办法,但无法证明是最佳的,也无法对其解决方案加以限定。最近的工作表明,强化学习可以成功地用于推动制约程序(CP)解决方案的搜索阶段。然而,还表明,这种混合化具有挑战性,因为标准CP框架并不本地地包括机器学习机制,从而导致效率低下。本文为SeaPearl提供了灵活性概念的证明,这是在朱莉亚实施的一个新的混合方案解决方案解决方案解决方案解决方案,支持机器学习常规常规,以便学习部门决定,同时利用强化绩效学习。支持我们学习了两个解决方案的模型,同时也为未来解决方案提供了一种解决方案的模型。