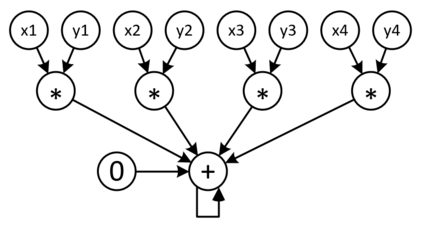
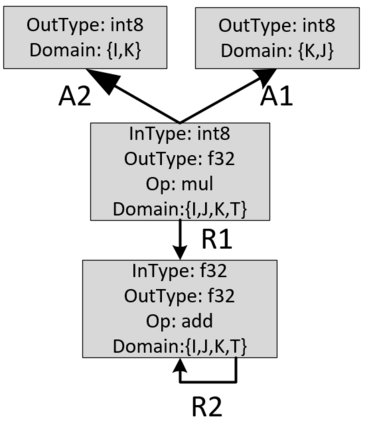
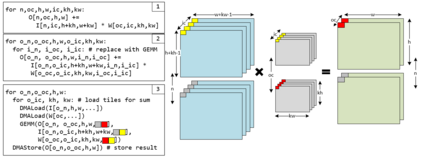
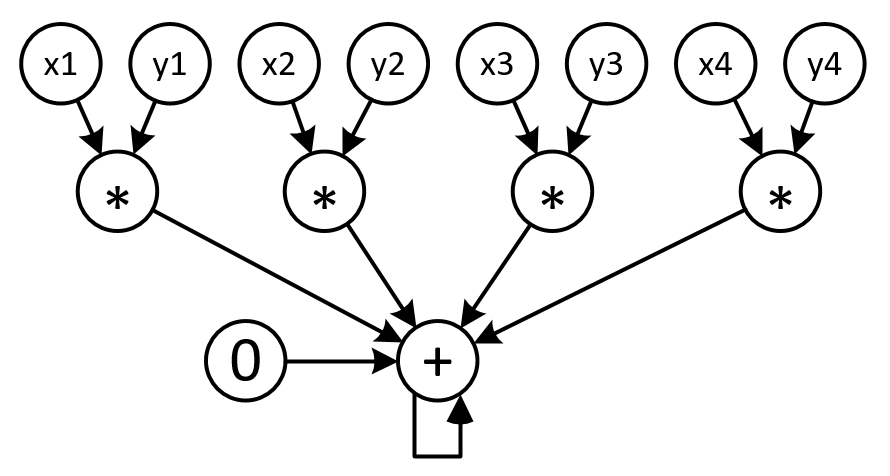
The success of Deep Artificial Neural Networks (DNNs) in many domains created a rich body of research concerned with hardware accelerators for compute-intensive DNN operators. However, implementing such operators efficiently with complex instructions such as matrix multiply is a task not yet automated gracefully. Solving this task often requires complex program and memory layout transformations. First solutions to this problem have been proposed, such as TVM or ISAMIR, which work on a loop-level representation of operators and rewrite the program before an instruction embedding into the operator is performed. This top-down approach creates a tension between exploration range and search space complexity. In this work, we propose a new approach to this problem. We have created a bottom-up method that allows the direct generation of implementations based on an accelerator's instruction set. By formulating the embedding as a constraint satisfaction problem over the scalar dataflow, every possible embedding solution is contained in the search space. By adding additional constraints, a solver can produce the subset of preferable solutions. A detailed evaluation using the VTA hardware accelerator with the Baidu DeepBench inference benchmark suite shows that our approach can automatically generate code competitive to reference implementations, and furthermore that memory layout flexibilty can be beneficial for overall performance. While the reference implementation achieves very low hardware utilization due to its fixed embedding strategy, we achieve a geomean speedup of up to x2.49, while individual operators can improve as much as x238.
翻译:深人工神经网络(DNNS)在许多领域的成功创造了大量与硬件加速器有关的大量研究,涉及计算密集 DNN操作员的硬件加速器。 然而, 以矩阵乘法等复杂指示高效率地执行这些操作员, 并不容易实现自动化。 解决这项任务往往需要复杂的程序和记忆布局转换。 已经提出了这一问题的第一个解决方案, 例如 TVM 或 ISAMIR, 后者在操作员执行指令之前, 工作于操作员的循环级别代表, 并重写程序。 这种自上而下的方法在计算密集的 DNNNN操作员的硬件加速器和搜索空间复杂度之间造成了紧张关系。 在这项工作中, 我们提出了一种新的方法。 我们创建了一种自下而上的方法, 使直接生成基于一个加速器指令设置的直接执行模式。 通过将这种嵌入成一个制约性满意度问题, 所有可能的嵌入式解决方案都包含在搜索空间中。 通过增加额外的制约, 解决者可以生成更佳的解决方案。 在这项工作中, 使用VTA 硬件参照器的参照度和搜索空间的复杂空间的搜索系统, 将显示一个可自动地平缩缩缩缩化的操作, 。