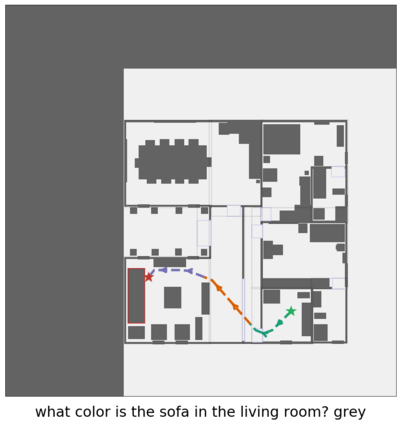
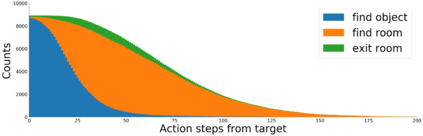
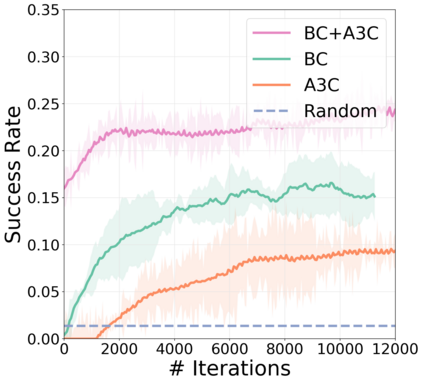
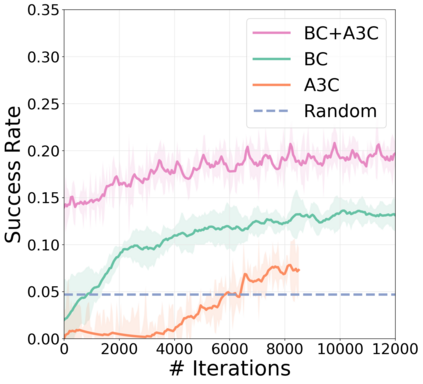
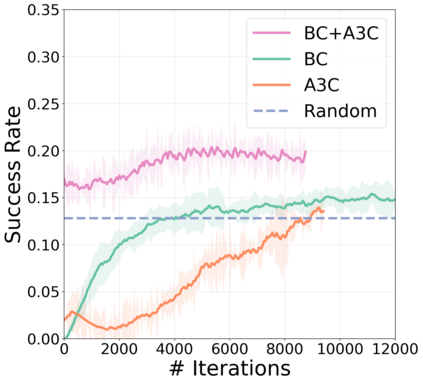
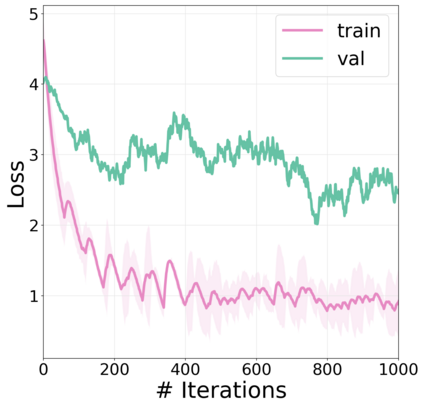
We present a modular approach for learning policies for navigation over long planning horizons from language input. Our hierarchical policy operates at multiple timescales, where the higher-level master policy proposes subgoals to be executed by specialized sub-policies. Our choice of subgoals is compositional and semantic, i.e. they can be sequentially combined in arbitrary orderings, and assume human-interpretable descriptions (e.g. 'exit room', 'find kitchen', 'find refrigerator', etc.). We use imitation learning to warm-start policies at each level of the hierarchy, dramatically increasing sample efficiency, followed by reinforcement learning. Independent reinforcement learning at each level of hierarchy enables sub-policies to adapt to consequences of their actions and recover from errors. Subsequent joint hierarchical training enables the master policy to adapt to the sub-policies. On the challenging EQA (Das et al., 2018) benchmark in House3D (Wu et al., 2018), requiring navigating diverse realistic indoor environments, our approach outperforms prior work by a significant margin, both in terms of navigation and question answering.
翻译:我们从语言投入中为长期规划角度的导航学习政策提出了一个模块化方法。我们的等级政策在多个时间尺度上运作,高级总体政策提出次级目标,由专门的次级政策执行。我们对子目标的选择是构成和语义性的,即可以在任意命令中相继结合,并假定人的解释性描述(例如“出场室”、“精密厨房”、“精密冰箱”等)。我们利用模仿学习,在等级层次的每个层次上制定温暖的启动政策,大大提高抽样效率,然后是强化学习。各级的独立强化学习使次政策能够适应其行动的后果并从错误中恢复过来。随后的联合等级培训使主政策能够适应次级政策。关于Hous3D(Wu等人等人等人,2018年)中具有挑战性的 EQA(Das等人,2018年)基准,要求通航现实的室内环境多样化,我们的方法在导航和问题解答两方面都比先前的工作有很大的距离。