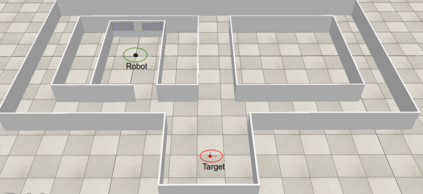
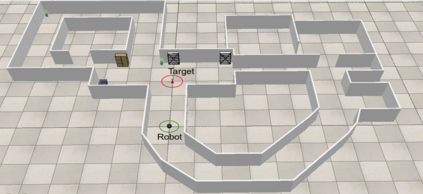
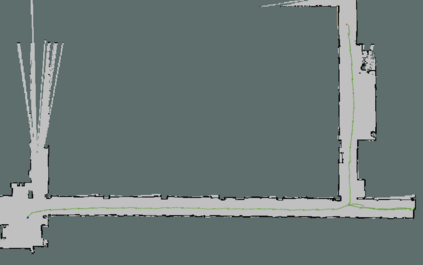
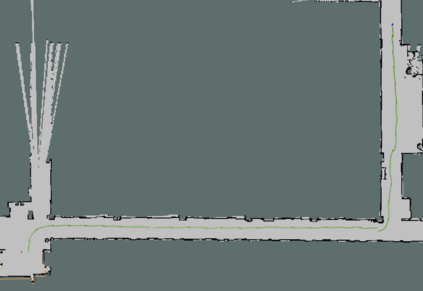
In this paper, we study the application of DRL algorithms in the context of local navigation problems, in which a robot moves towards a goal location in unknown and cluttered workspaces equipped only with limited-range exteroceptive sensors, such as LiDAR. Collision avoidance policies based on DRL present some advantages, but they are quite susceptible to local minima, once their capacity to learn suitable actions is limited to the sensor range. Since most robots perform tasks in unstructured environments, it is of great interest to seek generalized local navigation policies capable of avoiding local minima, especially in untrained scenarios. To do so, we propose a novel reward function that incorporates map information gained in the training stage, increasing the agent's capacity to deliberate about the best course of action. Also, we use the SAC algorithm for training our ANN, which shows to be more effective than others in the state-of-the-art literature. A set of sim-to-sim and sim-to-real experiments illustrate that our proposed reward combined with the SAC outperforms the compared methods in terms of local minima and collision avoidance.
翻译:在本文中,我们研究了当地导航问题背景下DRL算法的应用情况,其中机器人向一个目标地点移动,其目标位置为未知和杂乱的工作空间,仅配备有限距离的外向感应传感器,如LIDAR。基于DRL的避免碰撞政策有一些优点,但是一旦他们学习适当行动的能力限于传感器范围,它们就很容易被当地迷宫所利用。由于大多数机器人在非结构化环境中执行任务,因此非常希望寻求能够避免当地迷你现象的通用当地导航政策,特别是在未经过训练的场景中。为了做到这一点,我们提议一种新的奖励功能,将培训阶段获得的地图信息纳入其中,提高代理人审议最佳行动方针的能力。此外,我们使用SAC算法来培训我们的ANN,这在最新文献中比其他人更有效。一套模拟到Sim和模拟到现实实验表明,我们提议的奖励加上SAC在本地迷你和避免碰撞方面比的方法。