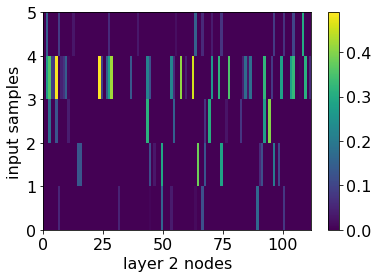
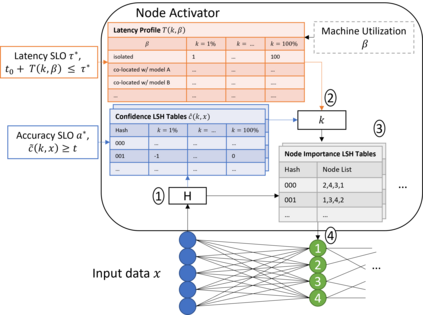
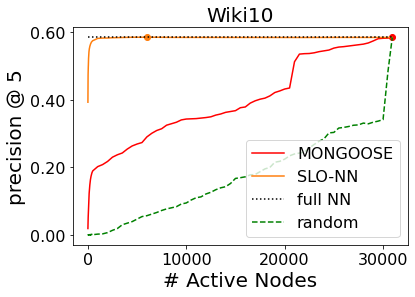
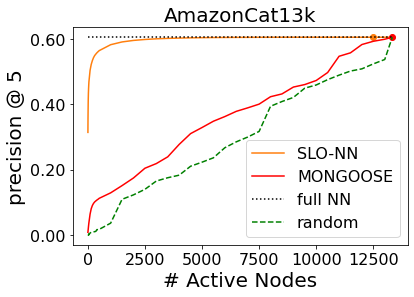
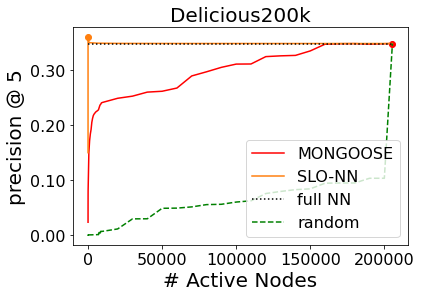
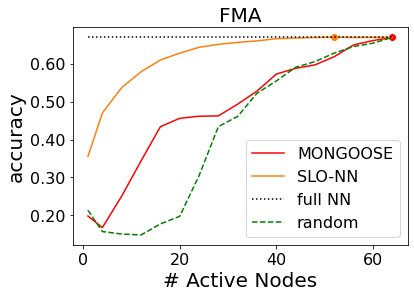
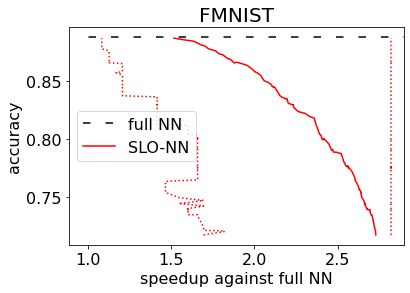
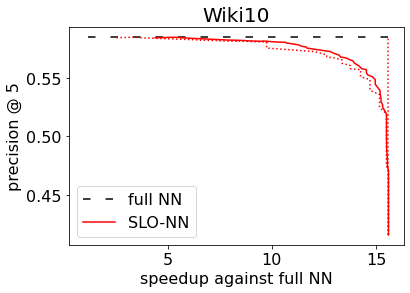
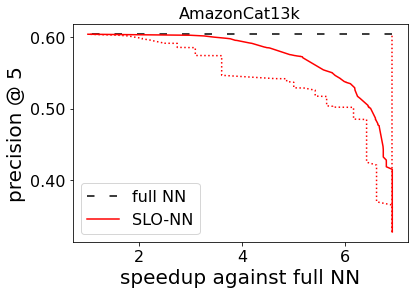
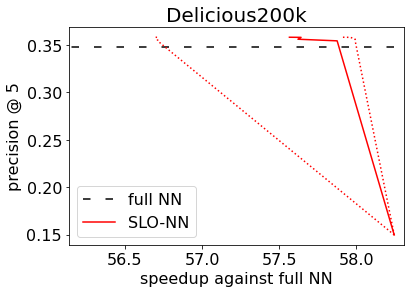
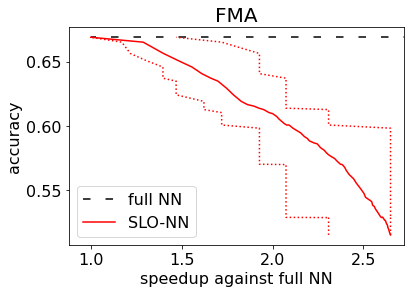
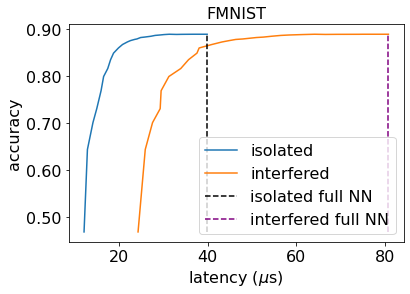
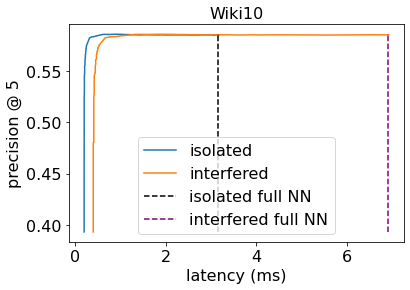
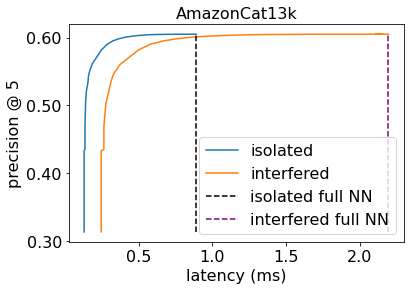
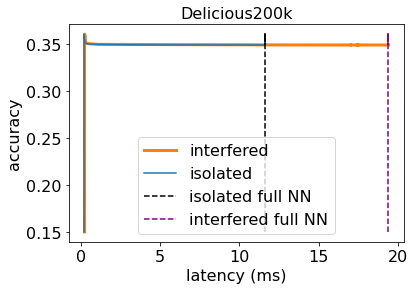
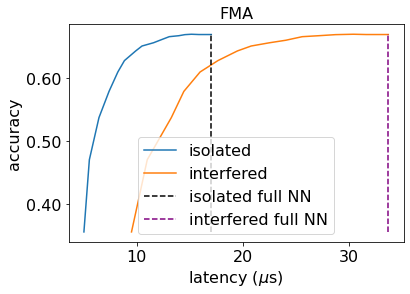
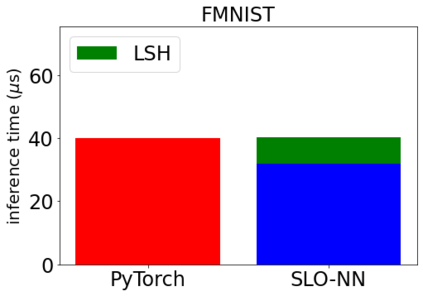
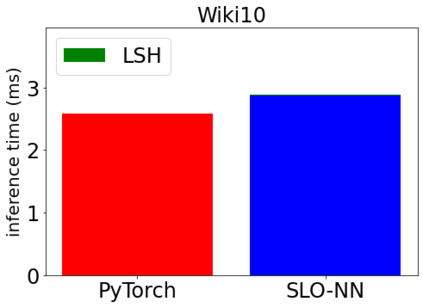
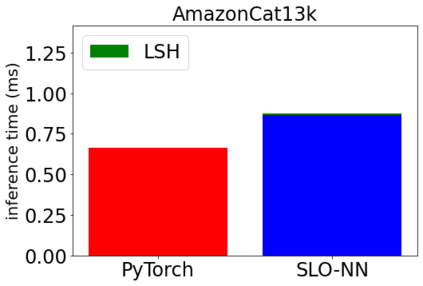
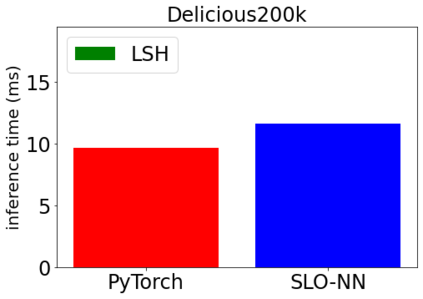
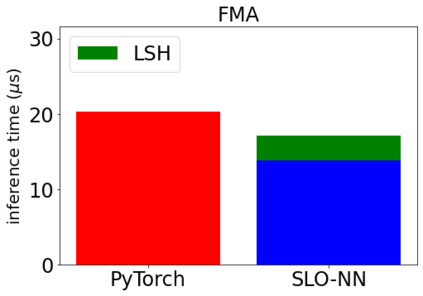
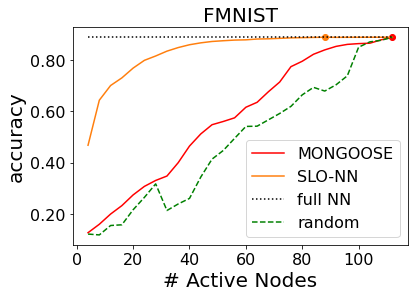
Machine learning (ML) inference is a real-time workload that must comply with strict Service Level Objectives (SLOs), including latency and accuracy targets. Unfortunately, ensuring that SLOs are not violated in inference-serving systems is challenging due to inherent model accuracy-latency tradeoffs, SLO diversity across and within application domains, evolution of SLOs over time, unpredictable query patterns, and co-location interference. In this paper, we observe that neural networks exhibit high degrees of per-input activation sparsity during inference. . Thus, we propose SLO-Aware Neural Networks which dynamically drop out nodes per-inference query, thereby tuning the amount of computation performed, according to specified SLO optimization targets and machine utilization. SLO-Aware Neural Networks achieve average speedups of $1.3-56.7\times$ with little to no accuracy loss (less than 0.3%). When accuracy constrained, SLO-Aware Neural Networks are able to serve a range of accuracy targets at low latency with the same trained model. When latency constrained, SLO-Aware Neural Networks can proactively alleviate latency degradation from co-location interference while maintaining high accuracy to meet latency constraints.
翻译:机器学习(ML)推断是一项实时工作量,必须符合严格的服务级目标(SLOs),包括长期性和准确性指标。不幸的是,由于固有的模型精确度偏差、应用领域之间和内部的 SLO多样性、SLO时间的演变、不可预测的查询模式和合用地点的干扰,确保SLO不受违反,这具有挑战性,因为在推断期间神经网络中,必须符合严格的服务级目标(SLOs),包括隐蔽性和准确性指标。因此,我们提议SLO-A软件神经网络,这些网络能动态地退出节点/perinference查询,从而根据规定的SLO优化目标和机器利用情况调整计算数量。 SLO-A软件神经网络平均速度增速1.3-56.7美元,几乎不会造成准确性损失(低于0.3 % ) 。在精确度受限时,SLO-A软件神经网络能够以同一经过训练的模式在低纬度处提供一系列准确性目标。当延缓度限制时,SLO-A软件网络能够保持高度降低度的干扰度,同时保持高度稳定度稳定度稳定度,同时保持高度稳定度稳定度,同时保持高度限制,同时保持高度神经网络可以满足高度。