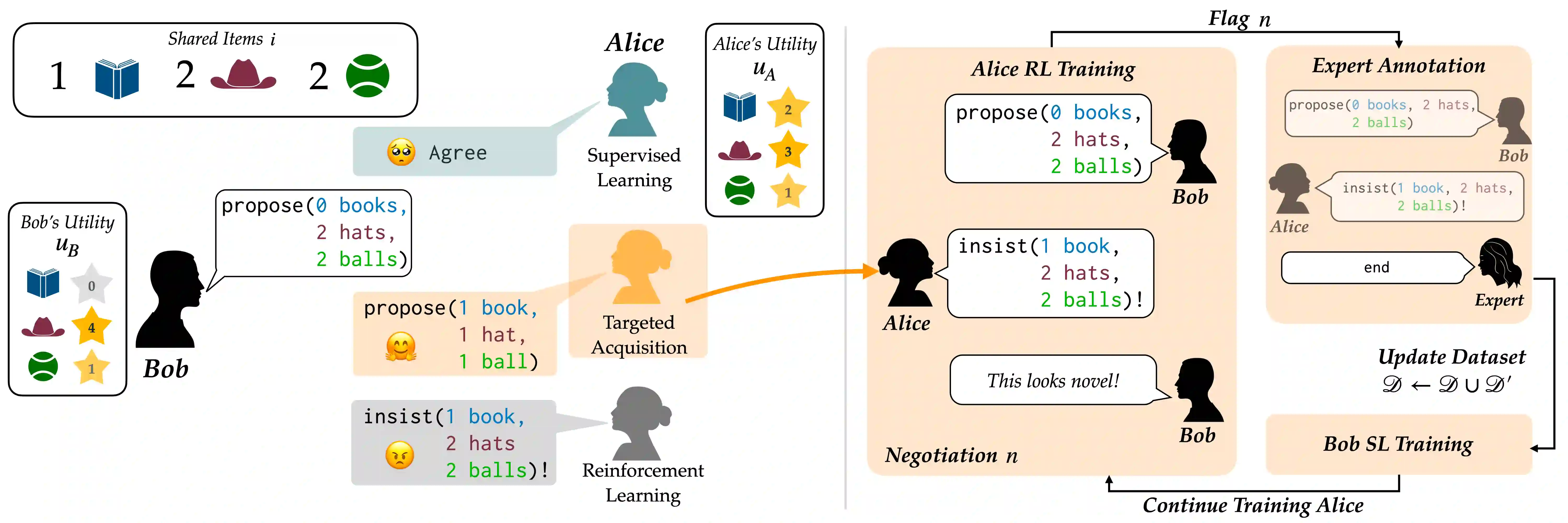
Successful negotiators must learn how to balance optimizing for self-interest and cooperation. Yet current artificial negotiation agents often heavily depend on the quality of the static datasets they were trained on, limiting their capacity to fashion an adaptive response balancing self-interest and cooperation. For this reason, we find that these agents can achieve either high utility or cooperation, but not both. To address this, we introduce a targeted data acquisition framework where we guide the exploration of a reinforcement learning agent using annotations from an expert oracle. The guided exploration incentivizes the learning agent to go beyond its static dataset and develop new negotiation strategies. We show that this enables our agents to obtain higher-reward and more Pareto-optimal solutions when negotiating with both simulated and human partners compared to standard supervised learning and reinforcement learning methods. This trend additionally holds when comparing agents using our targeted data acquisition framework to variants of agents trained with a mix of supervised learning and reinforcement learning, or to agents using tailored reward functions that explicitly optimize for utility and Pareto-optimality.
翻译:成功的谈判者必须学会如何平衡最佳自我利益与合作。然而,目前的人工谈判者往往严重依赖他们所培训的静态数据集的质量,限制了他们制定平衡自我利益与合作的适应性反应的能力。 因此,我们发现这些代理者可以实现高效用或合作,但不能两者兼而有之。为了解决这个问题,我们引入了有针对性的数据获取框架,用以指导利用专家官官的注释来探索强化学习剂。指导性探索激励学习者超越静态数据集,并制定新的谈判战略。我们表明,这使我们的代理者在与模拟伙伴和人类伙伴谈判时获得更高回报和更多最佳的解决方案,而与标准监管的学习和加强学习方法相比。在将使用我们的目标数据获取框架的代理者与经过监督学习和强化学习组合培训的代理者或使用明确优化实用性和最佳性及优化的定制奖赏功能的代理者进行比较时,这一趋势将进一步维持。