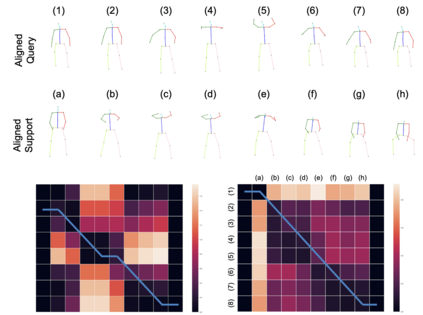
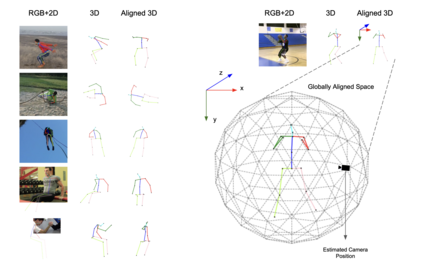
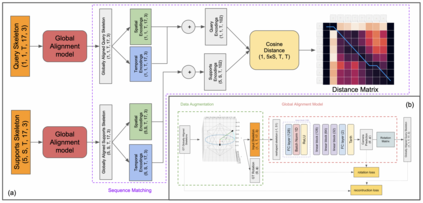
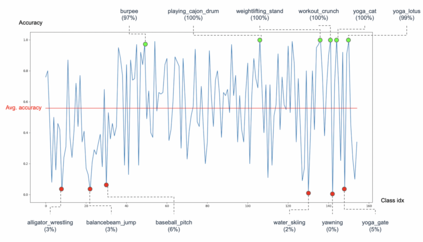
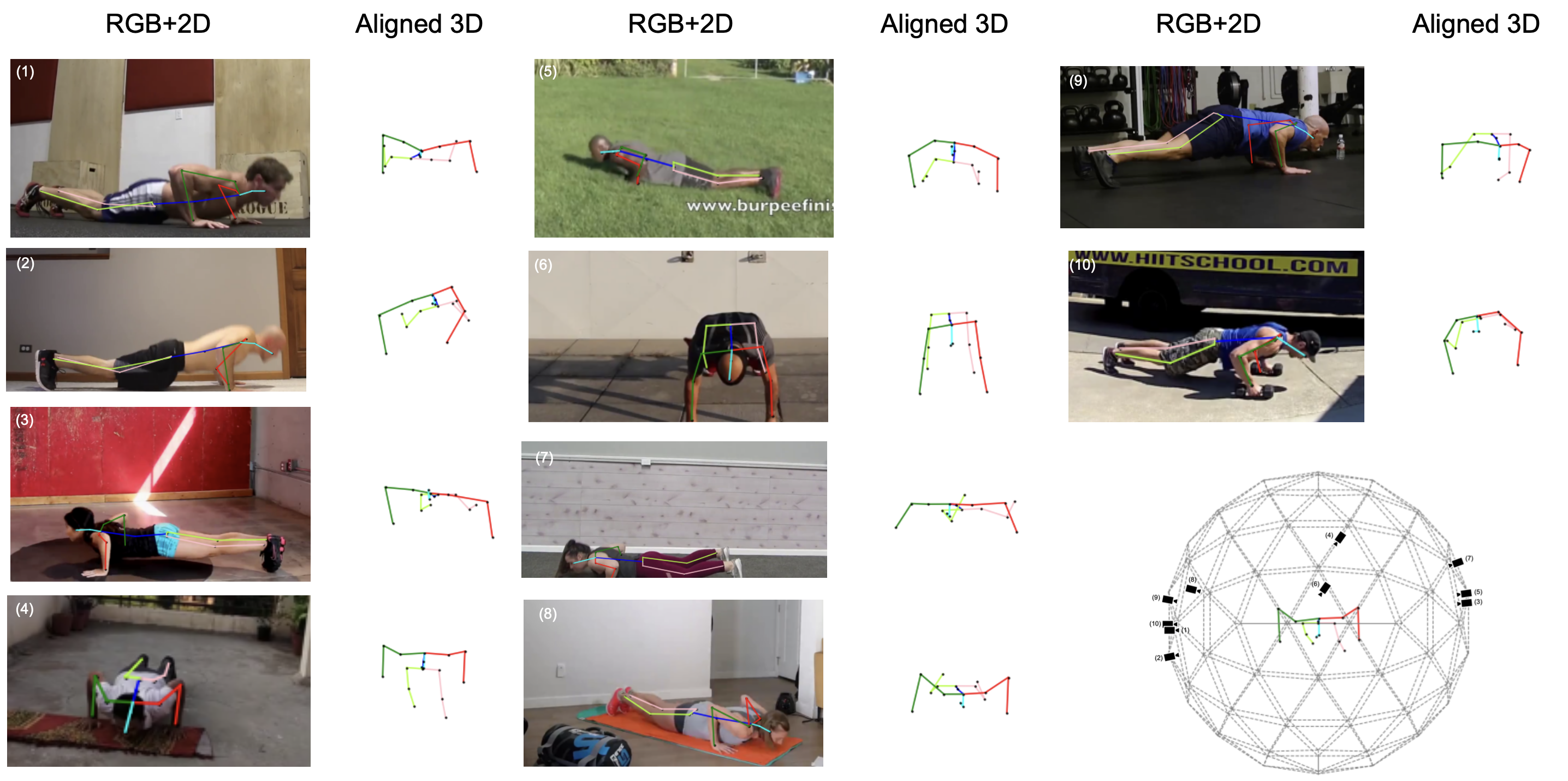
Human actions involve complex pose variations and their 2D projections can be highly ambiguous. Thus 3D spatio-temporal or 4D (i.e., 3D+T) human skeletons, which are photometric and viewpoint invariant, are an excellent alternative to 2D+T skeletons/pixels to improve action recognition accuracy. This paper proposes a new 4D dataset HAA4D which consists of more than 3,300 RGB videos in 300 human atomic action classes. HAA4D is clean, diverse, class-balanced where each class is viewpoint-balanced with the use of 4D skeletons, in which as few as one 4D skeleton per class is sufficient for training a deep recognition model. Further, the choice of atomic actions makes annotation even easier, because each video clip lasts for only a few seconds. All training and testing 3D skeletons in HAA4D are globally aligned, using a deep alignment model to the same global space, making each skeleton face the negative z-direction. Such alignment makes matching skeletons more stable by reducing intraclass variations and thus with fewer training samples per class needed for action recognition. Given the high diversity and skeletal alignment in HAA4D, we construct the first baseline few-shot 4D human atomic action recognition network without bells and whistles, which produces comparable or higher performance than relevant state-of-the-art techniques relying on embedded space encoding without explicit skeletal alignment, using the same small number of training samples of unseen classes.
翻译:人类行动涉及复杂的变异,它们的2D预测可能非常模糊。 因此, 3D的时空或4D( 即 3D+T) 人体骨骼是光度和观点变异的, 是2D+T骨架/像素的极好替代品, 以提高行动识别准确性。 本文提出一个新的 4D 数据集 HAA4D, 由300个人类原子行动类中3 300多个 RGB 视频组成。 高级高级A4D 是清洁的、 多样化的、 班级平衡的, 每一类与4D 骨架的使用相平衡, 其中每类只有一个4D 骨架, 足以训练深度识别模型。 此外, 选择原子行动动作更便于识别, 因为每个视频剪辑只持续几秒钟。 所有HAA4D的3D骨架都是全球一致的, 使用与同一全球空间的深度校正模型, 使每个骨架都面临负的z- 方向。 这种校正使骨架与骨架相匹配更加稳定, 减少类内部变异, 并且每个班级培训样本, 使用不甚高的直径直径直径直径直径直径直径比的直径直径直径直径比, 的直径直径直径直径直, 。