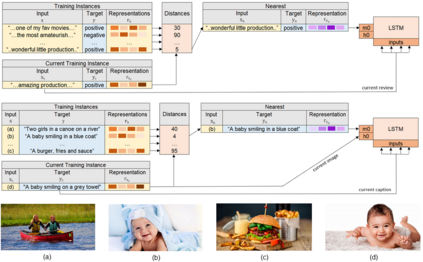
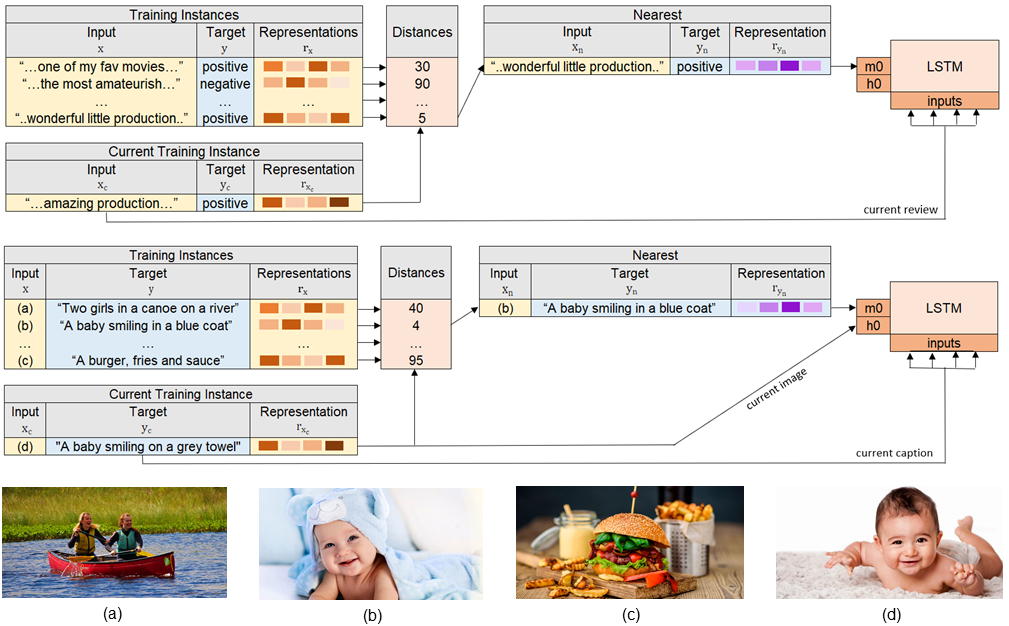
Deep neural network models have achieved state-of-the-art results in various tasks related to vision and/or language. Despite the use of large training data, most models are trained by iterating over single input-output pairs, discarding the remaining examples for the current prediction. In this work, we actively exploit the training data to improve the robustness and interpretability of deep neural networks, using the information from nearest training examples to aid the prediction both during training and testing. Specifically, the proposed approach uses the target of the nearest input example to initialize the memory state of an LSTM model or to guide attention mechanisms. We apply this approach to image captioning and sentiment analysis, conducting experiments with both image and text retrieval. Results show the effectiveness of the proposed models for the two tasks, on the widely used Flickr8 and IMDB datasets, respectively. Our code is publicly available http://github.com/RitaRamo/retrieval-augmentation-nn.
翻译:深神经网络模型在与视觉和/或语言有关的各种任务中取得了最先进的结果。尽管使用了大量的培训数据,但大多数模型都是通过对单一投入-产出配对的迭代来培训的,从而抛弃了目前预测的剩余实例。在这项工作中,我们积极利用培训数据来提高深神经网络的可靠性和可解释性,利用来自最近的培训实例的信息来帮助在培训和测试期间进行预测。具体地说,拟议方法使用最接近输入示例的目标来启动LSTM模型的记忆状态或指导关注机制。我们采用这一方法来进行图像说明和情绪分析,同时进行图像检索和文本检索实验。结果分别显示在广泛使用的Flickr8和IMDB数据集上拟议的两个任务模式的有效性。我们的代码公开提供http://github.com/RitaRAmo/retrieval-Augmentation-nn。