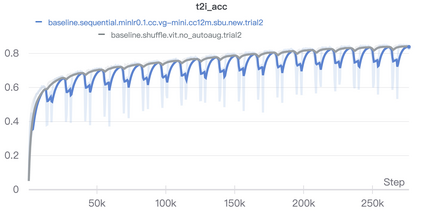
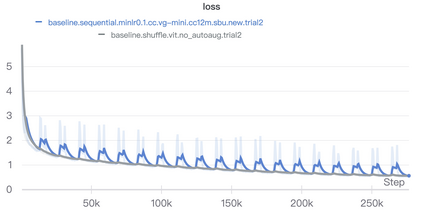
Pioneering dual-encoder pre-training works (e.g., CLIP and ALIGN) have revealed the potential of aligning multi-modal representations with contrastive learning. However, these works require a tremendous amount of data and computational resources (e.g., billion-level web data and hundreds of GPUs), which prevent researchers with limited resources from reproduction and further exploration. To this end, we explore a stack of simple but effective heuristics, and provide a comprehensive training guidance, which allows us to conduct dual-encoder multi-modal representation alignment with limited resources. We provide a reproducible strong baseline of competitive results, namely ZeroVL, with only 14M publicly accessible academic datasets and 8 V100 GPUs. Additionally, we collect 100M web data for pre-training, and achieve comparable or superior results than state-of-the-art methods, further proving the effectiveness of our method on large-scale data. We hope that this work will provide useful data points and experience for future research in multi-modal pre-training. Our code is available at https://github.com/zerovl/ZeroVL.
翻译:培训前工作(如CLIP和ALIGN)揭示了使多模式代表与对比学习相结合的潜力,然而,这些工作需要大量数据和计算资源(如10亿级网络数据和数百个GPU),这使资源有限的研究人员无法复制和进一步探索,为此,我们探索了一系列简单而有效的超光速学,并提供了全面的培训指导,使我们能够在有限的资源下进行双编码多模式代表调整。我们提供了可复制的竞争性结果的强有力基线,即ZeroVL,只有14M可公开查阅的学术数据集和8V100GPUs。此外,我们收集了100M网络数据,用于培训前,并取得了比最新技术方法可比或优越的结果,进一步证明了我们大规模数据方法的有效性。我们希望这项工作将为未来多模式培训前的研究提供有用的数据点和经验。我们的代码可在 https://github.L/comzerovl查阅 https://github./Verovl。