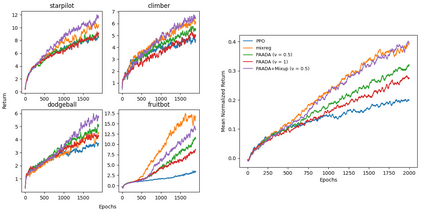
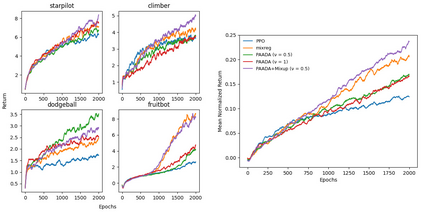
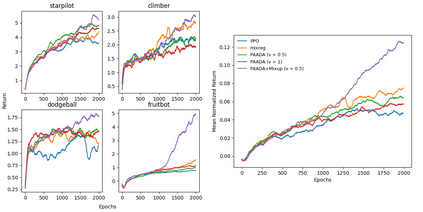
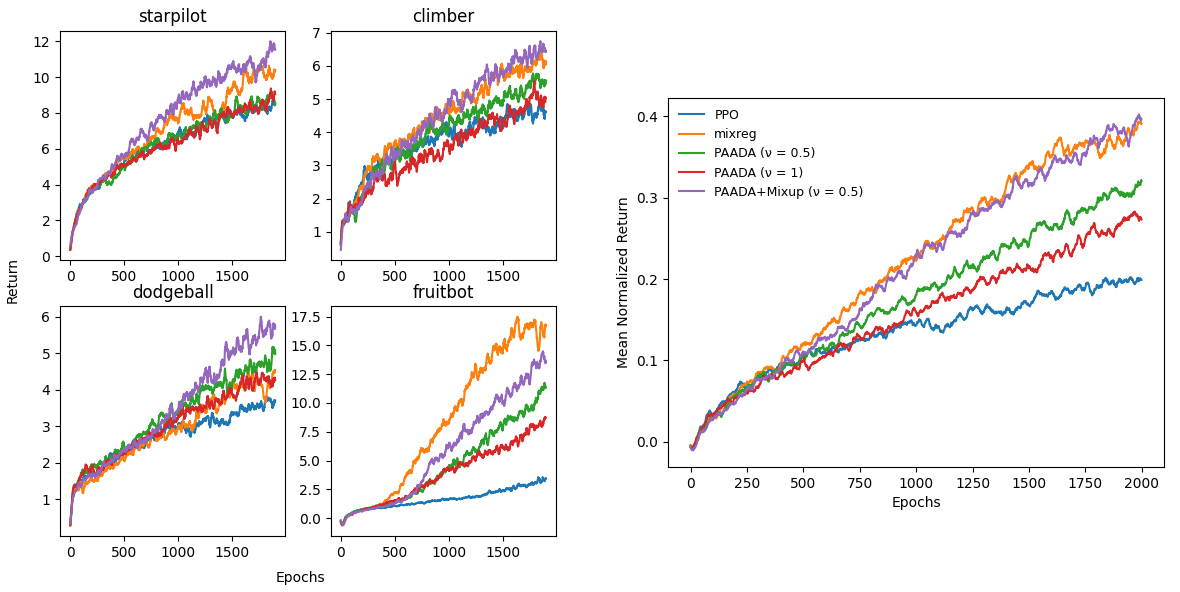
The generalization gap in reinforcement learning (RL) has been a significant obstacle that prevents the RL agent from learning general skills and adapting to varying environments. Increasing the generalization capacity of the RL systems can significantly improve their performance on real-world working environments. In this work, we propose a novel policy-aware adversarial data augmentation method to augment the standard policy learning method with automatically generated trajectory data. Different from the commonly used observation transformation based data augmentations, our proposed method adversarially generates new trajectory data based on the policy gradient objective and aims to more effectively increase the RL agent's generalization ability with the policy-aware data augmentation. Moreover, we further deploy a mixup step to integrate the original and generated data to enhance the generalization capacity while mitigating the over-deviation of the adversarial data. We conduct experiments on a number of RL tasks to investigate the generalization performance of the proposed method by comparing it with the standard baselines and the state-of-the-art mixreg approach. The results show our method can generalize well with limited training diversity, and achieve the state-of-the-art generalization test performance.
翻译:强化学习的普遍化差距(RL)一直是阻碍RL代理商学习一般技能并适应不同环境的重大障碍。提高RL系统的普及能力可以大大改善他们在现实世界工作环境中的绩效。在这项工作中,我们提出一种新的具有政策意识的对抗性数据增强方法,以自动生成的轨迹数据增强标准政策学习方法。不同于常用的基于数据增强的观测转换方法,我们提议的对抗性方法根据政策梯度目标生成新的轨迹数据,目的是更有效地提高RL代理商在政策认知数据增强方面的普遍化能力。此外,我们进一步采取混合步骤,整合原始和生成的数据,以加强总体化能力,同时减轻对对抗性数据过度缓解。我们进行了一些RL任务实验,通过将拟议方法与标准基线和最新混合法方法进行比较,调查其总体化绩效。结果显示,我们的方法可以与有限的培训多样性相协调,并实现最先进的一般化测试性能。