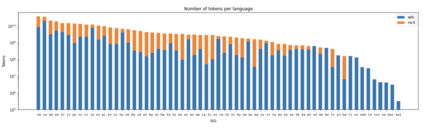
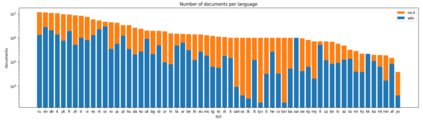
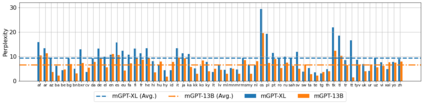
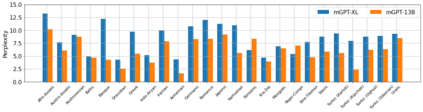
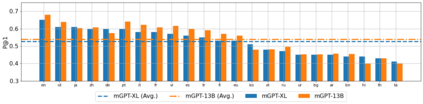
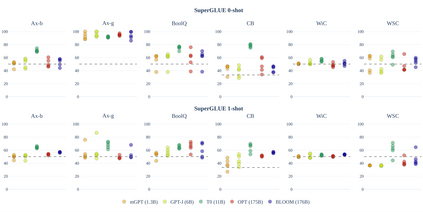
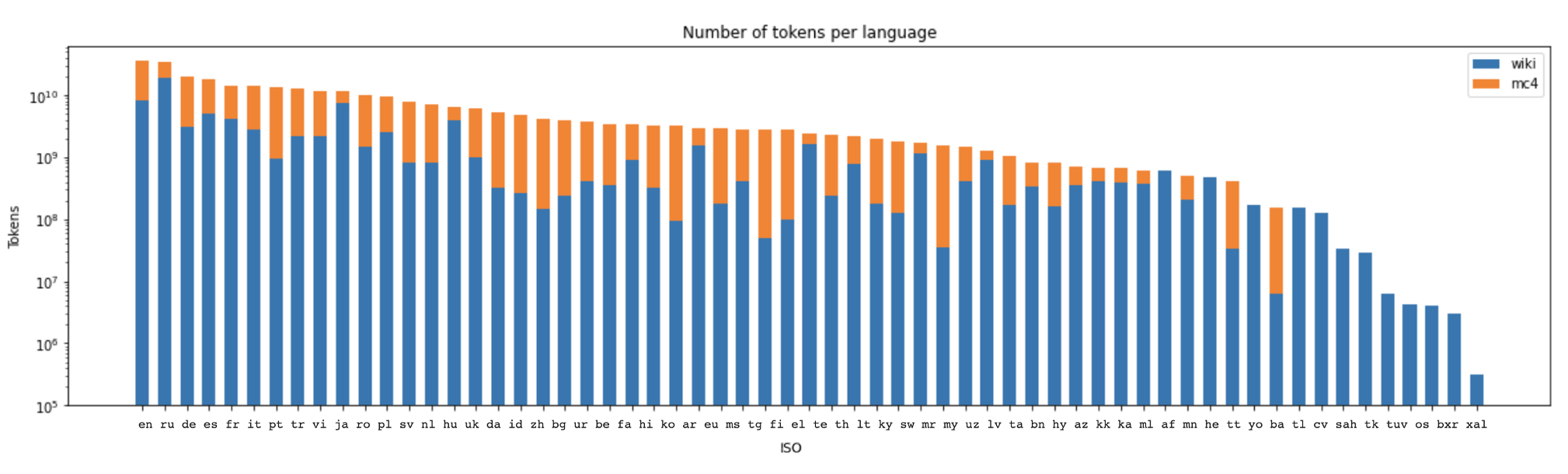
Recent studies report that autoregressive language models can successfully solve many NLP tasks via zero- and few-shot learning paradigms, which opens up new possibilities for using the pre-trained language models. This paper introduces two autoregressive GPT-like models with 1.3 billion and 13 billion parameters trained on 60 languages from 25 language families using Wikipedia and Colossal Clean Crawled Corpus. We reproduce the GPT-3 architecture using GPT-2 sources and the sparse attention mechanism; Deepspeed and Megatron frameworks allow us to parallelize the training and inference steps effectively. The resulting models show performance on par with the recently released XGLM models by Facebook, covering more languages and enhancing NLP possibilities for low resource languages of CIS countries and Russian small nations. We detail the motivation for the choices of the architecture design, thoroughly describe the data preparation pipeline, and train five small versions of the model to choose the most optimal multilingual tokenization strategy. We measure the model perplexity in all covered languages and evaluate it on the wide spectre of multilingual tasks, including classification, generative, sequence labeling and knowledge probing. The models were evaluated with the zero-shot and few-shot methods. Furthermore, we compared the classification tasks with the state-of-the-art multilingual model XGLM. source code and the mGPT XL model are publicly released.
翻译:暂无翻译