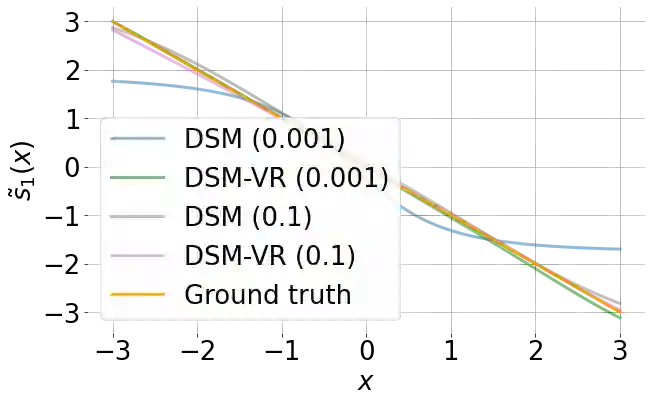
The first order derivative of a data density can be estimated efficiently by denoising score matching, and has become an important component in many applications, such as image generation and audio synthesis. Higher order derivatives provide additional local information about the data distribution and enable new applications. Although they can be estimated via automatic differentiation of a learned density model, this can amplify estimation errors and is expensive in high dimensional settings. To overcome these limitations, we propose a method to directly estimate high order derivatives (scores) of a data density from samples. We first show that denoising score matching can be interpreted as a particular case of Tweedie's formula. By leveraging Tweedie's formula on higher order moments, we generalize denoising score matching to estimate higher order derivatives. We demonstrate empirically that models trained with the proposed method can approximate second order derivatives more efficiently and accurately than via automatic differentiation. We show that our models can be used to quantify uncertainty in denoising and to improve the mixing speed of Langevin dynamics via Ozaki discretization for sampling synthetic data and natural images.
翻译:数据密度的第一阶衍生物可以通过分级比对来有效估算数据密度的第一阶衍生物,并已成为图像生成和音频合成等许多应用中的一个重要组成部分。 更高阶衍生物提供了更多关于数据分布的本地信息, 并启用了新的应用。 虽然可以通过对一个学习的密度模型进行自动区分来估算它们, 但是这可以扩大估计错误, 在高维环境下, 其成本昂贵。 为了克服这些限制, 我们建议了一种方法来直接估算样本数据密度的高阶衍生物( 分级) 。 我们首先显示, 分级比对可以被解释为 Tweedie 公式的一个特例 。 通过在更高顺序时刻利用 Tweedie 的公式, 我们用一般化的分级比对更高顺序衍生物进行估算。 我们从经验上证明, 接受过建议方法培训的模型可以比通过自动分级法更高效、更准确地估计第二阶衍生物。 我们表明, 我们的模型可以用来量化分解中的不确定性, 通过 Ozaki 分解和自然图像的混合速度。