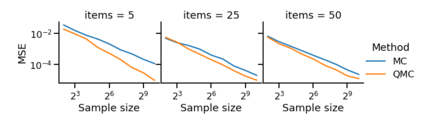
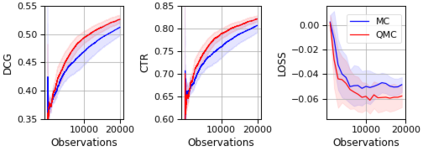
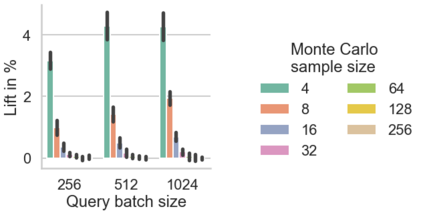
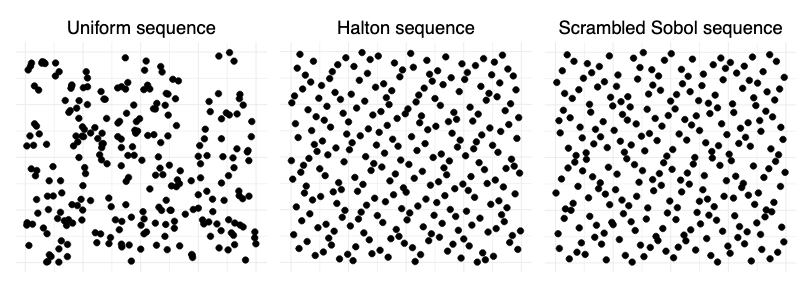
The Plackett-Luce (PL) model is ubiquitous in learning-to-rank (LTR) because it provides a useful and intuitive probabilistic model for sampling ranked lists. Counterfactual offline evaluation and optimization of ranking metrics are pivotal for using LTR methods in production. When adopting the PL model as a ranking policy, both tasks require the computation of expectations with respect to the model. These are usually approximated via Monte-Carlo (MC) sampling, since the combinatorial scaling in the number of items to be ranked makes their analytical computation intractable. Despite recent advances in improving the computational efficiency of the sampling process via the Gumbel top-k trick, the MC estimates can suffer from high variance. We develop a novel approach to producing more sample-efficient estimators of expectations in the PL model by combining the Gumbel top-k trick with quasi-Monte Carlo (QMC) sampling, a well-established technique for variance reduction. We illustrate our findings both theoretically and empirically using real-world recommendation data from Amazon Music and the Yahoo learning-to-rank challenge.
翻译:Plackett-Luce(Plackett-Luce)(Plackett-Luce)(PL)模式在学习到排名(LTR)方面无处不在,因为它为抽样排名列表提供了一个有用和直觉的概率模型。反事实离线评价和优化排名指标对于使用LTR方法的生产至关重要。在采用Plcl模式时,需要计算模型的预期值。这两项任务通常通过Monte-Carlo(MC)抽样方法进行,因为要排名的项目数量组合缩放使得其分析计算难以进行。尽管最近通过Gumberl 最高K 骗术在提高取样过程的计算效率方面取得了进展,但MC的估计可能存在很大差异。我们开发了一种新颖的方法,通过将 Gumbel 顶级诀窍与准Monte Carlo(QMC) 取样方法相结合,一种成熟的减少差异的技术,从而产生出更高效的PLPLS模型期望值的样本。我们用亚马孙音乐和Yahoo 学习到 挑战中真实世界建议数据来说明我们的调查结果。