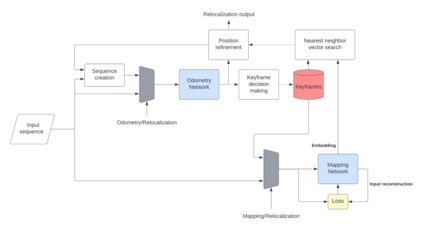
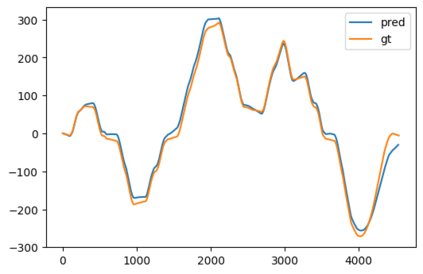
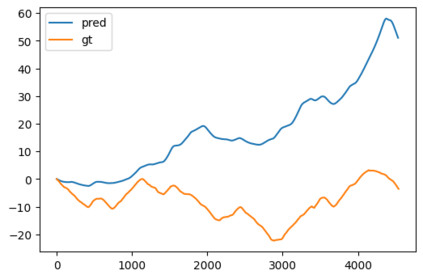
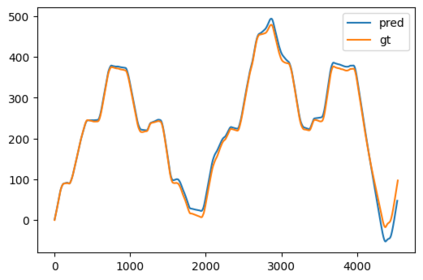
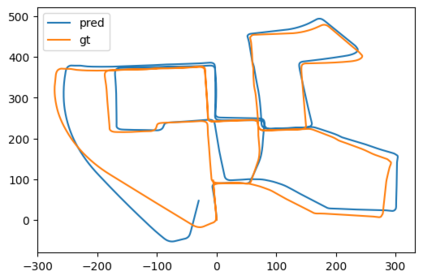
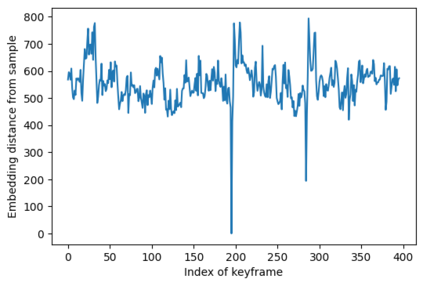
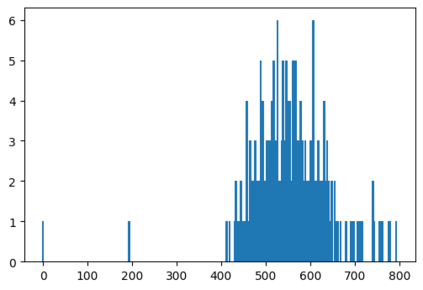
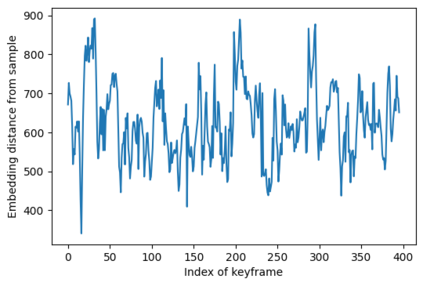
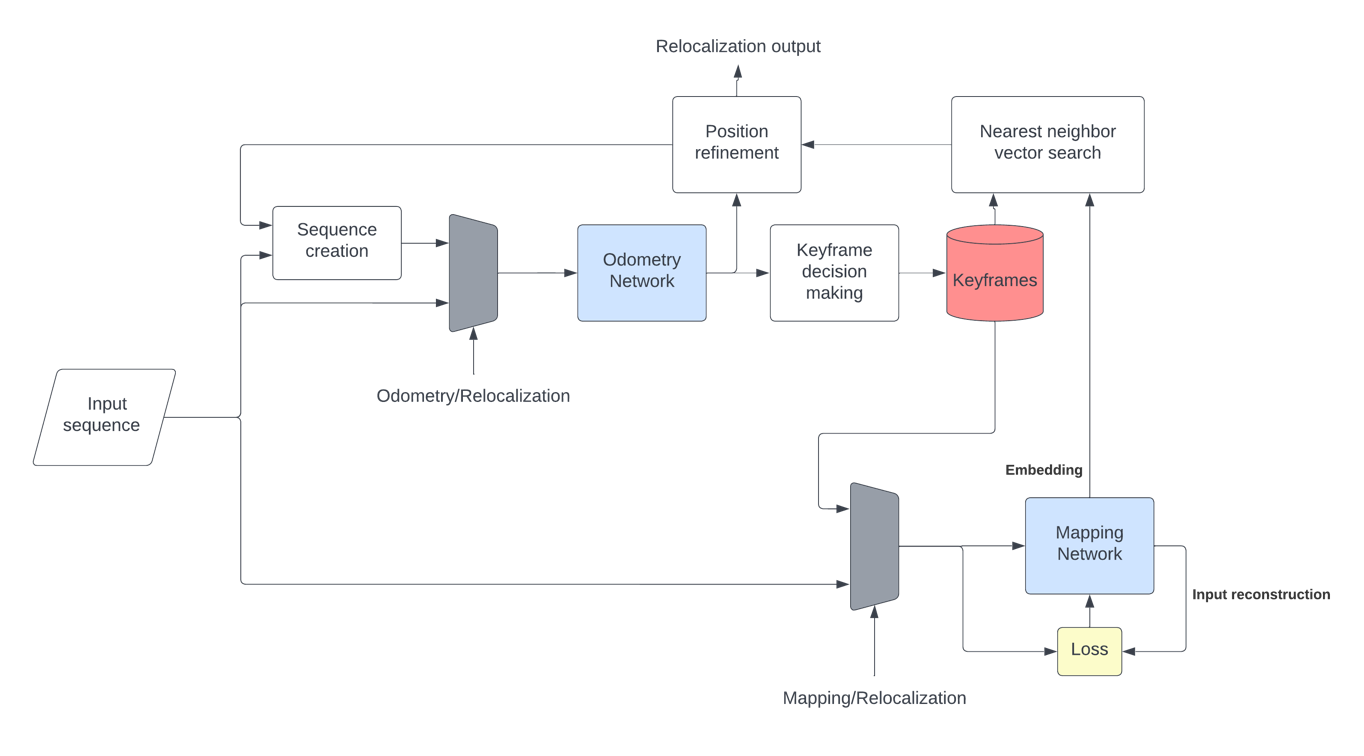
In this paper, a novel solution is introduced for visual Simultaneous Localization and Mapping (vSLAM) that is built up of Deep Learning components. The proposed architecture is a highly modular framework in which each component offers state of the art results in their respective fields of vision-based deep learning solutions. The paper shows that with the synergic integration of these individual building blocks, a functioning and efficient all-through deep neural (ATDN) vSLAM system can be created. The Embedding Distance Loss function is introduced and using it the ATDN architecture is trained. The resulting system managed to achieve 4.4% translation and 0.0176 deg/m rotational error on a subset of the KITTI dataset. The proposed architecture can be used for efficient and low-latency autonomous driving (AD) aiding database creation as well as a basis for autonomous vehicle (AV) control.
翻译:在本文中,为视觉同步本地化和绘图(VSLAM)引入了一个新解决方案,这是由深层学习构件组成的视觉同步本地化和绘图(VSLAM),拟议架构是一个高度模块化的框架,其中每个构件在各自的基于愿景的深层学习解决方案领域提供最新成果,文件表明,随着这些单个构件的协同整合,可以创建一个功能高效的全通深层神经系统(ATDN) vSLAM系统,引入嵌入远程损失功能,并使用ATDN架构。由此形成的系统在KITTI数据集的子集中实现了4.4%的翻译和0.0176 dig/m的旋转错误。拟议的架构可用于高效和低长度自主驱动(AD),帮助创建数据库,并用作自动飞行器控制的基础。