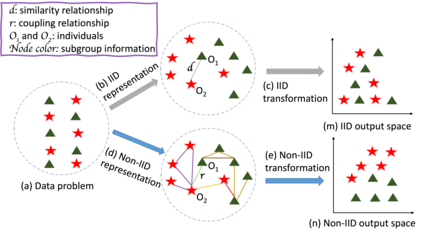
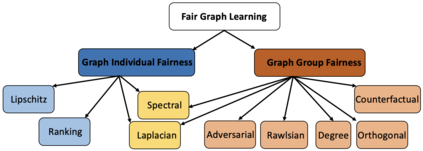
The importance of understanding and correcting algorithmic bias in machine learning (ML) has led to an increase in research on fairness in ML, which typically assumes that the underlying data is independent and identically distributed (IID). However, in reality, data is often represented using non-IID graph structures that capture connections among individual units. To address bias in ML systems, it is crucial to bridge the gap between the traditional fairness literature designed for IID data and the ubiquity of non-IID graph data. In this survey, we review such recent advance in fairness amidst non-IID graph data and identify datasets and evaluation metrics available for future research. We also point out the limitations of existing work as well as promising future directions.
翻译:理解和纠正机器学习中的算法偏差的重要性已导致对数学公平性的研究增加,这种研究通常假定基础数据是独立和相同分布的(IID)。然而,在现实中,数据往往使用非IID图表结构来表示,这种结构可以捕捉各个单元之间的联系。为了消除数学系统中的偏差,必须缩小为IDS数据设计的传统公平文献与非IID图表数据无处不在之间的差距。在这次调查中,我们审查了非IID图表数据中最近这种公平性的进展,并确定了可供今后研究使用的数据集和评价指标。我们还指出了现有工作的局限性以及有希望的未来方向。