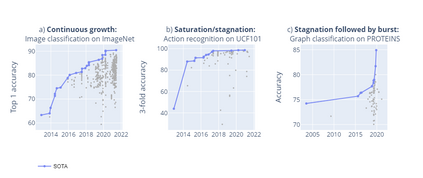
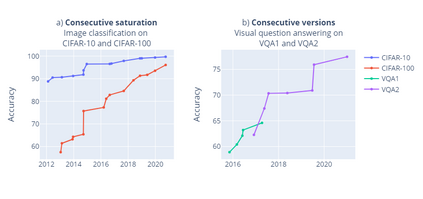
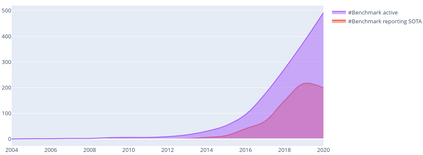
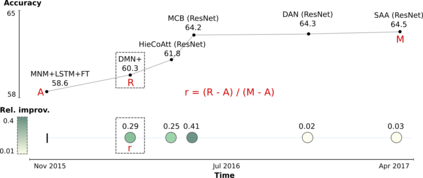
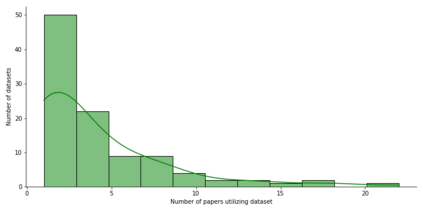
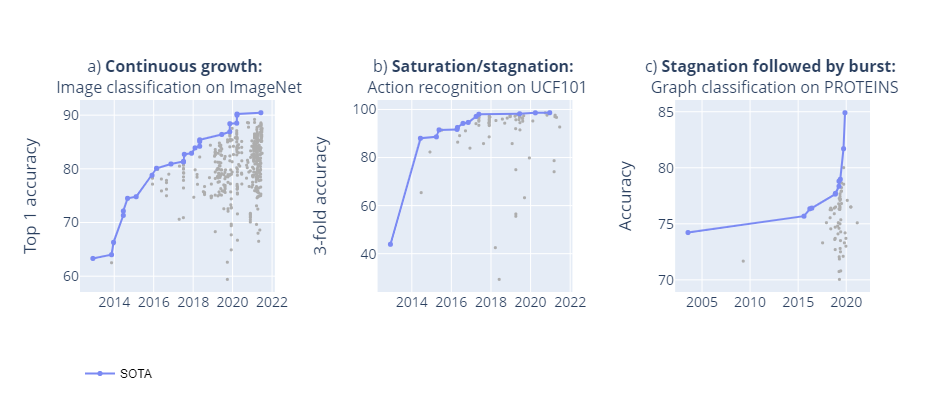
Benchmarks are crucial to measuring and steering progress in artificial intelligence (AI). However, recent studies raised concerns over the state of AI benchmarking, reporting issues such as benchmark overfitting, benchmark saturation and increasing centralization of benchmark dataset creation. To facilitate monitoring of the health of the AI benchmarking ecosystem, we introduce methodologies for creating condensed maps of the global dynamics of benchmark creation and saturation. We curated data for 1688 benchmarks covering the entire domains of computer vision and natural language processing, and show that a large fraction of benchmarks quickly trended towards near-saturation, that many benchmarks fail to find widespread utilization, and that benchmark performance gains for different AI tasks were prone to unforeseen bursts. We analyze attributes associated with benchmark popularity, and conclude that future benchmarks should emphasize versatility, breadth and real-world utility.
翻译:然而,最近的研究引起了人们对大赦国际基准状况的关切,报告的问题包括基准过大、基准饱和和和基准数据集的建立日益集中。为了便利监测大赦国际基准生态系统的健康,我们采用了编制全球基准创建和饱和动态简图的方法。我们整理了涵盖计算机愿景和自然语言处理等整个领域的1688年基准的数据,并表明大量基准迅速趋向接近饱和,许多基准没有得到普遍利用,以及不同大赦国际任务的基准绩效收益容易意外爆发。我们分析了与基准普及有关的属性,并得出结论,未来基准应强调多功能、广度和实际用途。