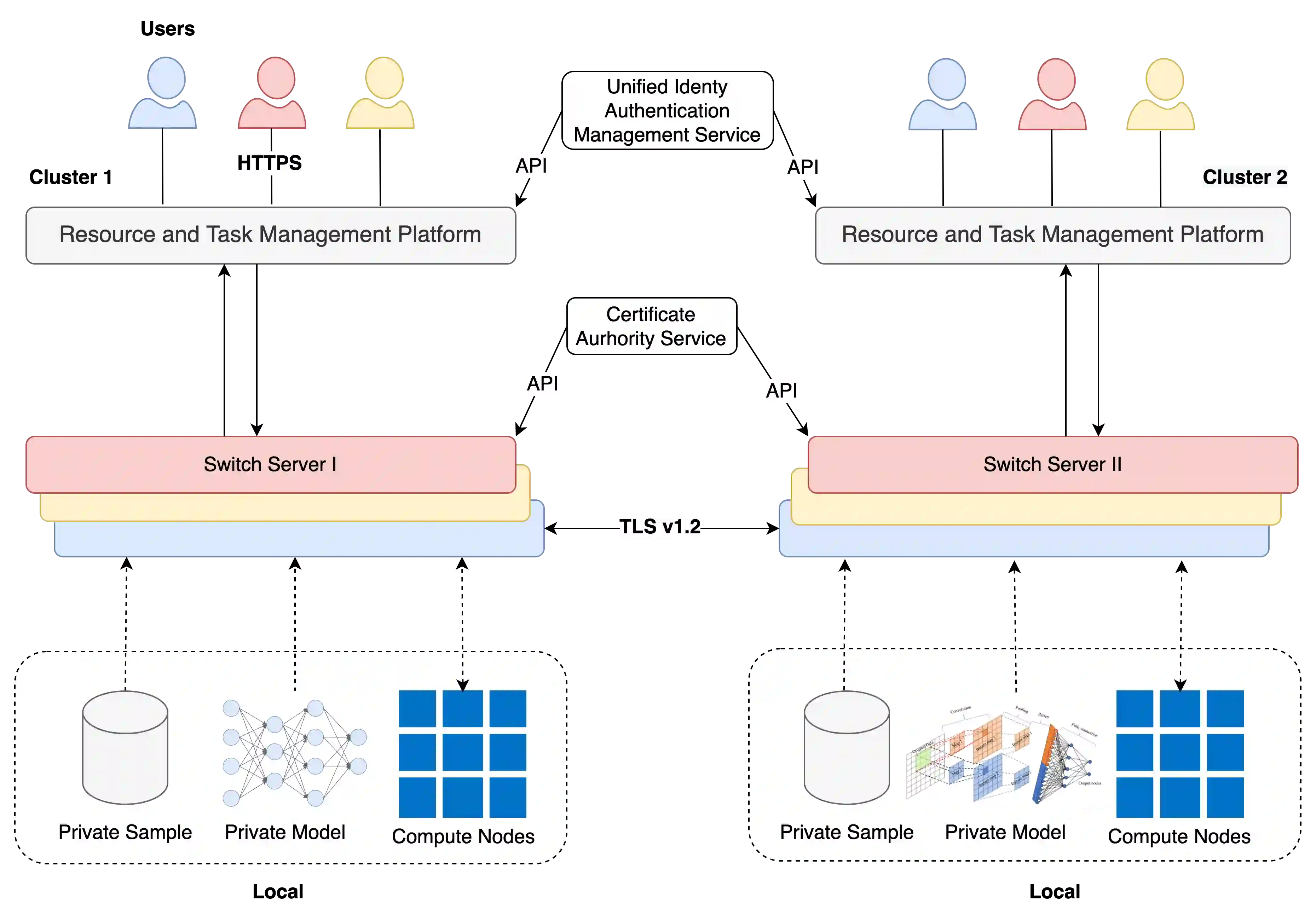
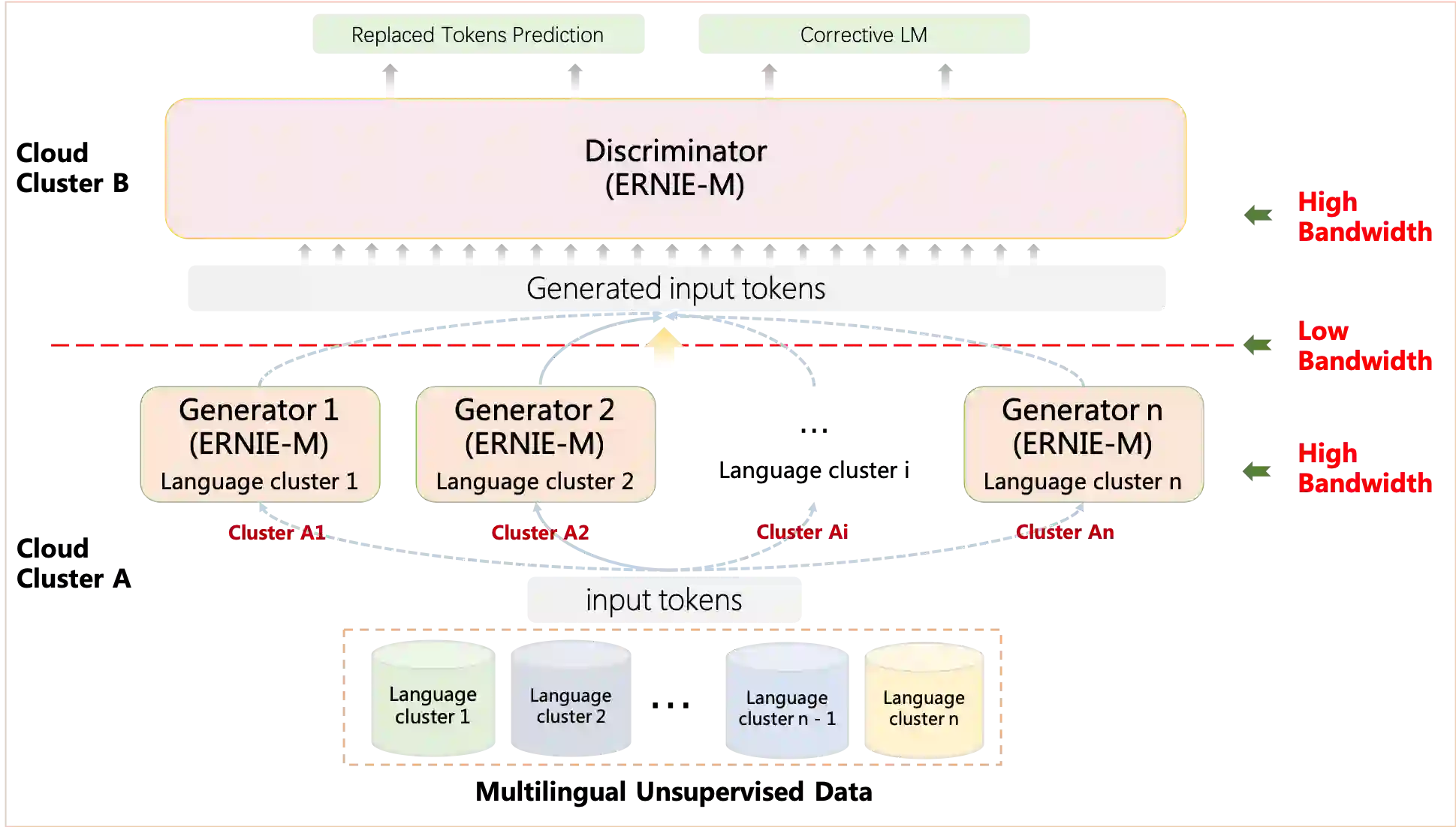
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
翻译:日益扩大的模型规模和计算规模吸引了越来越多的兴趣,在多个节点上培训深学习模式。然而,当涉及到云层集群培训时,特别是在偏远群组之间,面临着巨大的挑战。在这项工作中,我们引入了一个总体框架,即Nebula-I, 以合作方式培训远程不同群组的深学习模式,这些群群之间的联系是低带宽广域网络(WANs),我们采用了自然语言处理(NLP),以展示Nebula-I在不同培训阶段是如何工作的,包括:(a) 使用两个远程群组对多语言模型进行预培训;以及(b) 使用预先培训模式所精炼的知识精炼的机器翻译模式进行微调调整,这些模式贯穿了最近最受欢迎的深学习模式。为了平衡准确性和沟通效率,在Nebula-I, 参数高效的混合计算方法和适应性通信加速技术被联合使用。与此同时,安全战略被用来保证内部集级计算和跨集群通信的安全、可靠性和隐私。 Nebula-I在NadlyPal-B-B-Blead-B-B-B-B-L-L-L-L-L-L-L-L-I-L-L-L-L-L-L-L-L-L-I-L-L-L-T-B-B-B-B-B-B-B-L-L-B-L-B-B-B-B-B-B-L-L-L-B-B-B-B-B-B-B-B-B-B-B-B-B-B-B-C-L-L-C-C-C-B-B-B-L-L-L-L-B-B-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-L-